Clustering temporal edition profiles of Wikipedia articles using HMM

Contents |
Introduction
In this report we propose a temporal study of the edition process on Wikipedia articles. Our grounding hypothesis is that the edition of articles follows from temporal processes characterized by bursts of activity [Kleinberg, 2002], and that these differ in magnitude, frequency, etc. according to the type of the article (conflicting article, particular topic).
For instance, if we consider for a particular article the evolution of the number of distinct contributors every month, we observe periods of greater activity of the Wikipedian community on this article. Here we consider a temporal series for each article: the number of deleted characters in a revision. We extracted different types of articles and performed clustering. The aim is to discover differences in the generating process of the articles according to their originating type, such as peaks frequency, observations frequency, observed values, etc. Our method could also be used to determine particular periods of greater activity in the articles.
Method
Model
We first selected a model. We chose hidden Markov models because they are well suited for temporal data, they take into account the characteristics previously mentioned (frequency, values) and they can usually be easily interpreted.
We made several important choices for the model :
- we simplified the problem to stationary processes, considering that for a particular article and over the few months of its existence time would have little effect.
- we chose first order HMM, assuming that the probability density of emission only depends on the current state, and that this state only depends on the previous state.
- we only used HMM with 2 or 3 states: these states actually correspond to the intuitive idea of activity: low, medium or high for starters.
- no transitions between states were forbidden: we could have chosen for instance to forbid direct transitions from low to high activity, avoiding the state of medium activity. If it is the case that such transition is not relevant, it should appear in the parameter estimates.
- we chose Poisson laws for the output probability densities in each state, which have been extensively used for data extracted from counting, that is for modelling the law followed by the random variable determining the number of times a given event happens in a given period. In our case, this variable will for instance be the number of deleted characters during an article revision.
Algorithm
Our aim is to automatically cluster article samples, each article being characterized by a temporal observation sequence. Our unsupervised clustering algorithm is inspired from the K-means method but based on hidden Markov processes.
We used the initialization process proposed by Smyth in [Smyth, 1997], which presents an unsupervised sequence clustering method based on hidden Markov models. The initialization method clusters sequences according to the probability that they have been generated by the same hidden Markov model. It also builds the representative HMM for each group.
The result was then used as an input for the HMM-based clustering algorithm proposed by Schliep et al. [Schliep, 2003]. It iteratively looks for a partition of the articles into K clusters, simultaneously learning a hidden Markov model representative of each learnt cluster. The sequences are re-assigned to the K initial clusters during an iterative procedure inspired from the K-means method. It places them into the cluster corresponding to the most representative HMM and then updates the parameters of these HMM.
Experiments
Data
Wikipedia is a very rich corpus.
It is entirely saved in a database of about 50 gigabytes for the
French-speaking version, which contains approximately
370,000 articles on April 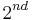 , 2006. The content of every page if fully available,
in HTML or in Wikitext language syntax. Wiki language is a simplified alternative to HTML
for writing texts.
, 2006. The content of every page if fully available,
in HTML or in Wikitext language syntax. Wiki language is a simplified alternative to HTML
for writing texts.
We used the French-speaking version of the encyclopedia. A dump of the database is regularly
updated on [1] and freely downloadable. Our database was created
on April , 2006. It contains 604,611 pages. Our aim is to study temporal activity profiles
of contributors on the articles of the encyclopedia, and to observe differences in the edition process.
For this purpose, we extracted different types of articles and then characterized
each article by an activity profile.
We limited our study to pages from the main namespace (Article) namespace, which accounts for Wikipedia's encyclopedic content and represents the great majority of pages, which is 368,426 pages. Among these article pages, we eliminated the 100,338 redirect pages. These pages only redirect users to the correct page (for instance in the case of synonyms), and thus don't undergo enough changes for the purpose of our study. At this stage we have 268,088 pages left.
On this basis, we selected different article samples:
- a random sample of 221 articles ;
- all articles labeled by a specific thematic category:
- category Mouvement artistique (art movements, 91 articles) was chosen as a debatable topic that could give rise to collaboration and excitement (positive or negative) among contributors.
- category Droit constitutionnel (constitutional law, 69 articles) was chosen for opposite reasons: we presupposed some unbiased characteristic of its articles. This objectivity is quite relative since the category contains not only law definitions but also more debatable articles.
- the 155 articles member of the 84 categories beginning with the string Gastronomie (gastronomy), chosen as a very popular topic not only reserved to expert contributors.
- 70 articles that suffered from an edit war, declared as wikifeu (wikifire) and extinguished by wikipompiers (wikifiremen). These volunteer wikipedians exist as Cabalists, in the English-speaking Wikipedia.
Results
We first mixed together the random sample and the wikifire pages. The following table shows the confusion matrix resulting from the unsupervised classification of this dataset.
| Decision + | Decision - | |
| Wikifeu | 65 | 5 |
| Random | 63 | 158 |
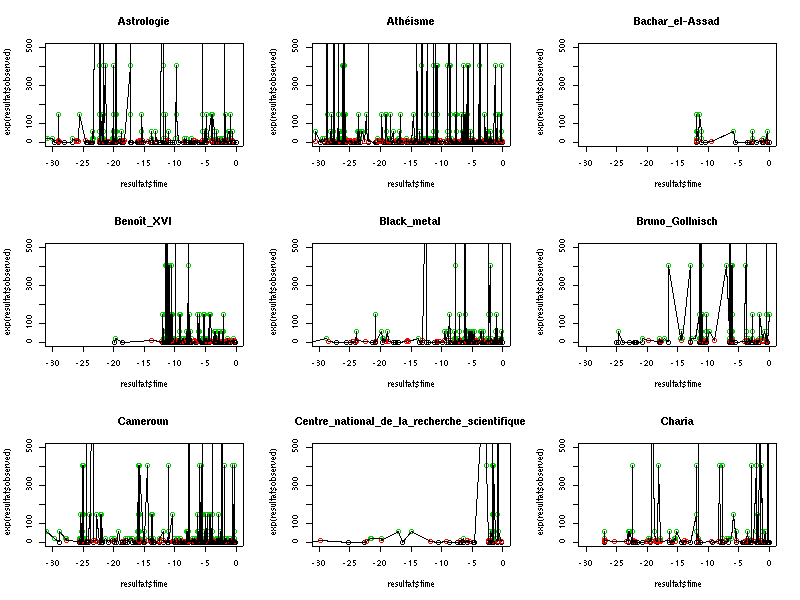
Recall is excellent (93%), precision is not very high (51%) and the F-mesure is quite important (66%). The image below illustrates examples of temporal profiles for 9 wikifeu articles.
We then mixed the articles from the art, law and gastronomy categories. The idea was to highlight differences in the edition process according to the topic concerned and thus according to the community of contributors. Next table shows the confusion matrix resulting from the automatic clustering on this other dataset. As we can observe, the different samples are scattered quite similarly in the confusion table. This would invalidate our hypothesis. However, before making such conclusions, it is necessary to try the experiment on other thematic categories, and with other kinds of data (number of contributors, etc.).
| Decision 1 | Decision 2 | Decision 3 | Total | |
| Mouvement artistique | 45% (25) | 33% (20) | 23% (15) | 60 |
| Droit constitutionnel | 28% (16) | 39% (24) | 27% (17) | 57 |
| Gastronomie | 27% (15) | 28% (17) | 50% (32) | 64 |
| Total | 100% (56) | 100% (61) | 100% (64) | 181 |
References
- J. Kleinberg. Bursty and hierarchical structure in streams. In 8th Proc. 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, July 2002.
- L. R. Rabiner. A tutorial on hidden markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2):257–286, 1989.
- A. Schliep, A. Schonhuth, and C. Steinhoff. Using hidden Markov models to analyze gene expression time course data. Bioinformatics, 19(suppl 1) :i255–263, 2003.
- P. Smyth. Clustering Sequences with Hidden Markov Models. In M. C. Mozer, M. I. Jordan, and T. Petsche, editors, Advances in Neural Information Processing Systems, volume 9, page 648. The MIT Press, 1997.