Information extraction using syntactic features for Question Answering
Contents |
Object
Question answering (QA) aims at retrieving precise information in a collection of documents, typically the Web: a user can ask a question such as "Which buildings did Christo wrap?" and get the precise answers "the Reichstag, the Pont-Neuf bridge".
QA systems can be decomposed into four major steps: question analysis, document retrieval, document processing and answer extraction.
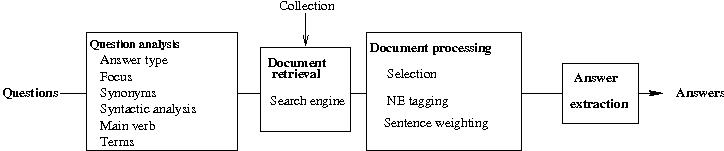
Answer extraction is generally based on named entity recognition, and syntactic analysis of the documents. These techniques require both reliable syntactic parsers, and large semantic bases, which are not always available. In order to implement a robust and easily adaptable answer extraction module, we chose to rely on local syntactic information instead.
Description
The existing answer extraction module first selects sentences in the documents according to their lexical proximity to the question, then extracts potential answers from the sentences. The extraction step depends on the expected answer type :
- if the question expects a named entity as an answer, the named entity of the expected type of the answer which is closest to the question words is selected. For example, the question "Who is the founder of Greenpeace?" expects a PERSON as an answer, and thus the named entity closest to the question words "founder" and "Greenpeace" in the sentences will be selected.
- otherwise, the potential answers are tagged according to their position with respect to the question words. For example, for the question "Who is Nick Leeson ?", a correct sentence is "Nick Leeson, Barings' former derivatives trader in Singapore, got hundreds of millions of pounds transferred from London to Singapore to help cover his trading losses.". As the nominal phrase "Barings' former derivatives trader" is separated from the question words "Nick Leeson" by a coma, it is tagged as a potential answer.
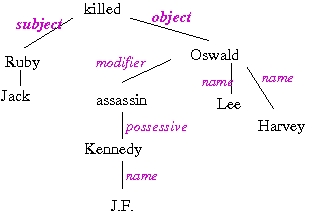
For some answers, these strategies are not sufficient: for the question "Who killed Lee Harvey Oswald ?", a correct answer is "Jack Ruby, who killed J.F.Kennedy's assassin Lee Harvey Oswald". As both "Jack Ruby" and "J.F.Kennedy" are tagged as PERSON, and "J.F.Kennedy" is closer to the question words "Lee Harvey Oswald", it is wrongly selected as the answer. Yet, the question analysis can detect that the answer should be subject of the verb "kill"; using the syntactic dependencies can help extract the answer. A complete analysis of the sentence is not necessary, since only the subject relation is used here.
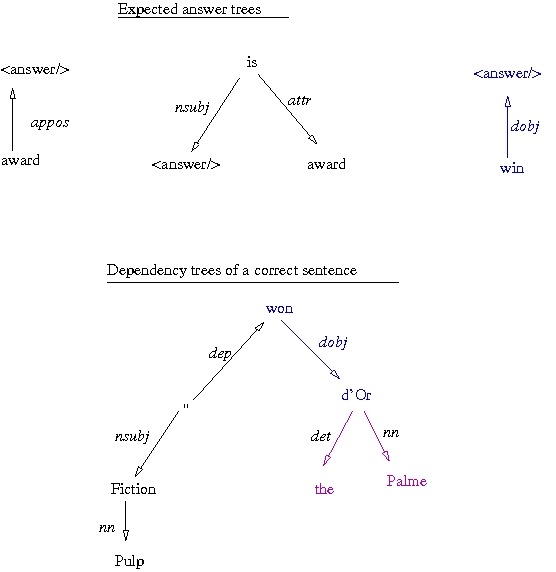
A strategy based on syntactic dependencies has been implemented, in order to improve the results of the answer extraction module. The principle is the following: first, the question is parsed to extract the expected dependency relations on the answer represented as a dependency tree; then equivalent dependency trees are generated, corresponding to the possible paraphrases of the question; finally, each sentence is parsed to test if it matches one of the previous trees.
For example, for the question "What award did Pulp Fiction win at the Cannes Film Festival?", the relation dobj(win, award) is extracted from the question parsing, and thus a relation "dobj(win, <reponse/>)" will be searched for in the sentences, as the following figure shows.
Results
This extraction strategy was evaluated in the English question answering system QALC on the corpus of 200 questions from the QA@CLEF 2005 evaluation campaign. The results for the existing answer extraction module are the following:
| Step | % of questions with a correct answer |
|---|---|
| First five sentences | 63% |
| First sentences | 45% |
| First five answers | 52% |
| First answers | 40% |
The strategy using local dependencies extraction enables to detect 33 correct answers, among which 12 are correct and 8 had not been extracted by the existing module. The results of the QALC system can thus be improved by adding this strategy.
References
Anne-Laure Ligozat, Exploitation et fusion de connaissances locales pour la recherche d'informations précises, PhD Thesis, Université Paris-Sud 11, 2006