Answer Justification: inference in multiple sources of knowledge
Brigitte Grau, Anne-Laure Ligozat, Isabelle Robba, Anne Vilnat and Vincent Barbier
Contents |
The CONIQUE project
In the Information Retrieval field, one of the current challenges concerns the ability of automatically finding the information searched by a user. The objective is to go further than the document retrieval paradigm, in which a user has to explore a list of documents for finding the information he searches for, and to let the retrieval system to perform the largest part of this work. This focus on precise information retrieval has raised a large interest for the question answering systems for the last few years and has led to several evaluation campaigns dedicated to this subject at the international level but also at the European and the national levels. The aim of a question answering system is to find the answer to a question, which is expressed in natural language, in a set of documents that may eventually be very large or even be the Web. Most of the question answering systems can extract the answer to a factoid question when this one is explicitly present in the texts but in the opposite case, they are not able to combine different pieces of information in reasoning for producing an answer.
The CONIQUE project aims at going beyond this insufficiency and takes place in a very active research area that focuses on introducing in question answering systems text understanding mechanisms relying on inferences. Unlike most of the work in this area, the first axis of our project has not the objective to build or to exploit an a priori knowledge base for answering to questions. It rather aims at modeling the extraction of this knowledge from different texts according to the need for building a path of inferences between the pieces of information found in the texts and the information that is searched by the user, as it is specified by a question.
The interest of the approach we propose is twofold: first, none knowledge base can contain all the knowledge for working with an open domain system. Second, when knowledge is extracted from texts, it can be associated to its context of use and validity, which can be extracted simultaneously. This context is particularly important for controlling the chaining of inferences and their validity in the search for an answer but it is also very interesting for presenting the result of this search process. Presenting the possible answers to a question within their respective contexts (date, location, viewpoint …) is a means for a user to understand the origin of their differences, which often result from the under specification of the initial question. This point is the second axis of our project.
The project is supported by ANR, and is one of the "projet blanc" of 2005, and is granted for three years. It is led in relation with the CEA/LIST lab., with Olivier ferret, and the MODYCO lab., with Jean-Luc Minel.
Answer justification : AVE.
At the moment, we worked on the justification part of an answer by using lexical criteria. In order to evaluate our propositions, we participated to the AVE (Answer Validation Exercice) task at CLEF. The goal of this exercise is to improve the performance of QA systems by developing methods for automatic evaluation of answers, and to make answer assessment semiautomatic. The organizers provided answers of QA systems with their supporting snippets, and the participants had to decide if each answer was correct or not according to the snippet. For example, the following couple (hypothesis, snippet) can be given:
Question: When was the Berlin wall demolished?
Answer: in 1989
Justification (supporting snippet): the Berlin wall divided East and West Berlin for 28 years, from the day construction began on August 13, 1961 until it was dismantled in 1989.
Lexical criteria for justification
In order to veify that the answer is correct or not, we define constraints on the answer formulation, automatically comptuted by the question analysis, and in a first approach we worked on lexical constraints. Question characteristics that are searched in the justification passage are the following :
- Terms, either single terms or multiple word terms, either in their original form or as a linguistic variant. In the example : Berlin Wall belongs to the passage, and demolish is present with a synonym ;
- Specific terms, that are directly in relation with the answer : the focus, that is the term that denotes the entity about which an information is searched (the Berlin wall in the example) and the answer type, that is either a named entity type (DATE in the example) or a type referred by a word of the question (as in "which building was wrapped by Christo ?", the answer has to be a building) ;
- Proximity of question terms in the passage. In an ideal word, a justificative passage has to be a paraphrase of the question, plus the answer. In order to approximate this notion, we calculate the longest chain of the passage that contains consecutive terms and evaluate it according to the ratio of words it contains ;
- Relation between the answer and the focus : the verification of this relation is done using extraction patterns, depending on the question category (definition, instance, characteristic, etc.) ;
- Verification of the answer type : if the type is in the passage, it can be verified by using a named entity recognizer or an extraction pattern with the phrase that designs the type as pivot element. If it is absent, it can be verify in an external ressources : we used Wikipedia.
Validating answers with a question answering system
We will see now how these verifications were implemented.
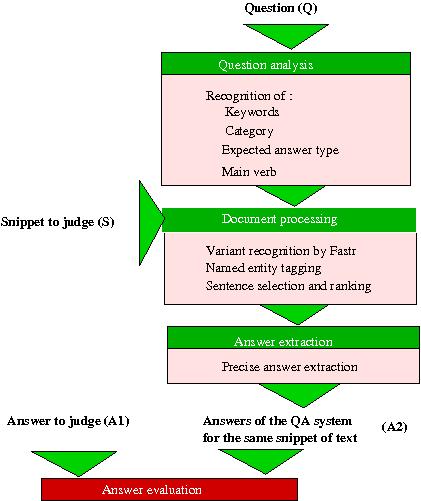
The answer validation system uses three out of the four modules of the FRASQUES question answering system as figure 1 shows. The input of the answer validation is a pair hypothesis-snippet, along with the original question Q and the answer to judge A1.
Fisrt, the question is analyzed by the Question analysis module, which processes a syntactic analysis of the question to detect some of its characteristics such as its keywords, the expected answer type (which can be a named entity like person, country, date... or a general type like conference or address), the focus of the question (which is defined as the entity about which a characteristic is required).
Then, the Document processing module is used, but on the snippet to judge instead of the output of the search engine. This module uses Fastr 3 to recognize linguistic variants of the question terms: for example, “Europe’s currency” will be recognized as a variant of “European currency”. Then the named entities of the documents are tagged with around 20 named entity types.
The Answer extraction module extract the anwer(s) A2 that is found by our system in the snippet. The extraction strategy depends on the expected type of the answer. If the answer is a named entity, the named entity of the expected type which is closest to the question words is selected. Otherwise, patterns of extraction are used. These patterns were written in the Cass 4 format, a syntactic parser used here for answer extraction instead of syntactic analysis. These rules express the possible position of the answer with respect to the question characteristics such as the focus or the expected type of the answer. Cass thus tags the answers in the candidate sentences.
Results
Finally, the answer A1 is evaluated, and the system returns YES if the answer is considered as justified or NO otherwise, with a confidence score. The decision algorithm proceeds in two main steps. During the first one, we detect quite evident mistakes, such as the answers which are completely enclosed in the question, or which are not part of the justification. When the question contains a date, this date is compared to the dates of the snippet, and if they are inconsistent, the pair is judged as a NO. The second step relies on the decision of a classification algorithm from the Weka toolbox, that takes as input the above criteria. The results obtained on the 2006 AVE data are shown on Table 1.
| Precision | Recall | F-measure |
|---|---|---|
| 0,58 | 0,82 | 0,68 |
Precision and recall are computed on the YES results.
References
Arnaud Grappy, Utilisation de méthodes lexicales pour la validation de réponses, M2R Informatique Paris Sud 11, septembre 2007
Anne-Laure Ligozat, Brigitte Grau, Anne Vilnat, Isabelle Robba, Arnaud Grappy, Towards an automatic validation of answers in Question Answering, 19th IEEE International Conference on Tools with Artiifcila Intelligence (ICTAI), 2007
Anne-Laure Ligozat, Brigitte Grau, Anne Vilnat, Isabelle Robba, Arnaud Grappy, Lexical validation of answers in Question Answering, The 2007 IEEE / WIC / ACM international conference on Web Intelligence (WI 07), 2007