DEFT'07: evaluation campaign on opinion text classification
Martine Hurault-Plantet, Cyril Grouin, Patrick Paroubek, Jean-Baptiste Berthelin
Contents |
Introduction

The Text Mining Challenge (DEFT for "Défi Fouille de Texte") is an annual competition in the field of text mining. The purpose of an evaluation campaign is to simultaneously test a set of various methods and programs from different research teams. As a by-product, the campaign provides a community with reference corpora [1].
In 2007, the DEFT challenge was, for the first time, organized by Limsi researchers, in coordination with the LRI lab, which had managed the two previous editions. The final workshop took place on July 3, 2007 in Grenoble, during the AFIA platform.
This year's topic was the automatic detection of opinion values within texts developing positive or negative judgments about various matters, along with relevant arguments. This is a classification task, which, for businesses, is a matter of data analysis and assisted decision-making, while for customers, it means sorting available items on the Internet and reach a conclusive judgment about them. Ten research teams took part in the challenge, two of them industrial (CELI France, Yahoo! R&D), and the other ones academic (EPHE/Universität Würzburg, GREYC/CRISCO, LGI2P/LIRMM, LIA and NLTG-University of Brighton), three of them consisting of young researchers only (Lattice, LIA, LIP6) [3].
Description
Corpus
A large part of the organizing job involved the collection and formatting of test corpora. Four of them were assembled, representing the three main topics of the challenge: the media (comments about books, films, shows and video games), science (comments by referees about scientific papers) and politics (debates in Parliament about proposed laws).
In most source corpora, marking scales were quite wide, the top marks being 5 or 6 for films and papers, and 20 for video games. To measure the difficulty of the task, we had human judges perform manual evaluation tests. These tests yielded a better agreement between judges (Kappa measure) for a scale of only three values. Therefore, in order to make the automatic task a feasible one, we reduced larger marking scales to three values only. However, the corpus of parliamentary debates, having only two values ("for" or "against" the proposed law), was left with this initial marking scale.
| Corpus | Description' | Marking scale |
| A voir à lire www.avoir-alire.com | 3,000 commentaries (7.6 Mo) about books, films and shows | 0:unfavorable, 1:neutral, 2:favorable |
| Video games www.jeuxvideo.com | 4,000 commentaries (28.3 Mo) about video games | 0:unfavorable, 1:neutral, 2:favorable |
| Paper reviews | 1,000 reviews (2.4 Mo) of scientific papers from JADT, RFIA et TALN | 0:paper rejected, 1:accepted subject to major edits, 2:accepted as such or with minor edits |
| Debates in Parliament | 28,800 interventions (38,1 Mo) by Representatives in the French Assembly | 0:voting against the proposed law, 1:voting for it |
Evaluation measurements
We used the F-score (with ß=1) to evaluate the competitors' results.
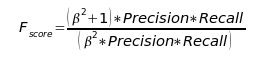
When the F-score is used to evaluate a classification's performance for each of n classes, global averages for precision and recall on the whole set of classes can be measured by the macro-average, which first calculates precision and recall for every class i, and averages them on the n classes. Each class, therefore, be it large or small, is equally weighted in the precision and recall measurement.
We calculated two types of F-score: a strict, deterministic one, assigning only one class to each document, and a weighted one, using a confidence measure which reflects the probability, for a document, to belong to each possible opinion class. Precision and recall are then weighted by the confidence measure.
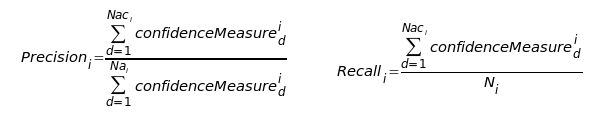
in which:
- Naci : number of documents d actually belonging to class i and to which the system gave a non-zero confidence measure for this class
- Nai : number of documents d to which the system gave a non-zero confidence measure for class i
- Ni : number of documents d belonging to class i
Each research team was allowed to send up to three result submissions, each submission containing results for all corpora.
Results and perspectives
Results
Ranking was performed according to each team's best submission. We give here the F-score obtained for the best submission of the first three competitors for each corpus, listed by incoming order [5]:
| Rank | Team | A voir à lire | Video games | Reviews | Debates |
| 01 | LIA (J.-M. Torres-Moreno, M. El-Bèze, F. Béchet, N. Camelin) | 0.602 | 0.784 | 0.564 | 0.719 |
| 02 | EPHE/U. Würzburg (M. Ahat, W. Lenhart, H. Baier, V. Hoareau, S. Jhean-Larose, G. Denhière) | 0.599 | 0.699 | 0.507 | 0.681 |
| 03 | CELI France (S. Maurel, P. Curtoni, L. Dini) | 0.513 | 0.706 | 0.536 | 0.697 |
Competitors have, as a rule, designed the process of assigning an opinion class to a document in two main steps: building a representation for the text, and then classifying it. Methods for doing that were quite diverse.
- Symbolic ones: linguistic processing, vocabulary for opinions, terms of the domain (focus/attractor) [4];
- Probabilistic and statistic ones: discriminating criteria for features and classifiers [2][6].
They proceeded by classifying the documents:
- by traditional classifiers (SVM, decision trees, logistic regression, neural networks, k-nearest neighbors, Bayes, similarity);
- by summing scores assigned to terms in the text [2];
- by hybrid methods: voting among various classifiers [4][6].
Perspectives
Tasks proposed so far within the DEFT challenge have been under the strong constraint of not depending on human judges to evaluate results from competitors. Instead of that, reference corpora contained the expected result. This is a restriction in the choice of the task, depending on the possibility, or impossibility, of elaborating corpora yielding a solution to the task. An interesting perspective, enlarging the field of possible tasks, would be the recuiting of human judges.
References
[1] Actes de l'atelier DEFT'07, Plate-forme AFIA 2007, Grenoble, Juillet 2007. http://deft07.limsi.fr/actes.php
[2] Ahat M., Lenhart W., Baier H., Hoareau V., Jhean-Larose S., Denhière G. (2007). "Une approche LSA au défi DEFT'07". In Actes de l'Atelier DEFT'07, Plate-forme AFIA 2007, Grenoble, Juillet 2007.
[3] Grouin C., Berthelin J-B., El Ayari S., Heitz T., Hurault-Plantet M., Jardino M., Khalis Z., Lastes M. (2007). "Présentation de DEFT'07 (Défi Fouille de Textes)". In Actes de l'Atelier DEFT'07, Plate-forme AFIA 2007, Grenoble, Juillet 2007.
[4] Maurel S., Curtoni P., Dini L. (2007). "Classification d'opinions par méthodes symbolique, statistique et hybride". In Actes de l'Atelier DEFT'07, Plate-forme AFIA 2007, Grenoble, Juillet 2007.
[5] Paroubek P., Berthelin J-B., El Ayari S., Grouin C., Heitz T., Hurault-Plantet M., Jardino M., Khalis Z., Lastes M. (2007). "Résultats de l'édition 2007 du Défi Fouille de Textes". In Actes de l'Atelier DEFT'07, Plate-forme AFIA 2007, Grenoble, Juillet 2007.
[6] Torres-Moreno J-M., El-Bèze M., Béchet F., Camelin N. (2007). "Comment faire pour que l'opinion forgée à la sortie des urnes soit la bonne ? Application au défi DEFT 2007". In Actes de l'Atelier DEFT'07, Plate-forme AFIA 2007, Grenoble, Juillet 2007.