EASy: Evaluation campaign for syntactic parsers of French
Patrick Paroubek, Isabelle Robba and Anne Vilnat
Contents |
Object
In natural language understanding, most of the complex systems use a syntactic parser as a basic functionality. The last decades have seen the emergence of a new class of systems: shallow parsers which provide only a surface structure analysis, while deep parsers that build full syntactic tree analysis have continued to be improved. Some parsers restrict themselves to identifying chunks (basic syntactic constituents of a phrase), others compute also the functional relations that exists between them, thus touching on semantics. The algorithms used for parsing range widely from classical automata or rule based ones, to statistical ones, the latter becoming more and more popular as the amount of data that a parser is required to process on average, increases drastrically along with the ever augmenting computer power.
Facing this diversity and the lack of a clear cut solution as to the best method to use for automatic parsing, the need for a comparative evaluation framework is more and more present, even more so since we do not have enough data on the way the performance of a parser can vary depending on the type of material it process, or the kind of annotation it is suppposed to yield. The 3 year EASY evaluation campaign has been the first attempt at providing an answer to this problem. EASY was part of a larger evaluation campaign named EVALDA, itself part of the national Technolangue program (http://www.technolangue.net), supported by the French Research Ministry. EASY is a complete evaluation protocol including:
- corpora constitution,
- manual corpora annotation using a dedicated annotation formalism,
- evaluation of the participating parsers,
- production of a large annotated and validated resource (a treebank).
Description
The annotation formalism lies at the heart of any comparative evaluation, since the chosen formalism must have a coverage as broad as possible of the syntactical phenomena while ensuring a fair treatment for all participants. In EASY, the choices made for the annotation formalism were made in concertation with the organizers, the participants and the corpus providers.
EASY has 6 types of chunks. They cannot be discontinuous nor embedded, and they must be as small as possible. Information which would not be expressed through chunks is expressed with functional relations. EASY has 14 of them. They can indifferently link constituents or word forms, or both.
Chunks 1 verbal phrase 2 nominal phrase 3 adjectival phrase 4 adverbial phrase 5 prepositional group introducing a nominal phrase 6 prepositional group introducing a verbal phrase PV Functional relations 1 subject-verb 2 auxiliary-verb 3 direct object-verb 4 complement-verb 5 modifier-verb 6 complement 7 attribute-subject/object 8 modifier-noun 9 modifier-adjective 10 modifier-adverb 11 modifier-preposition 12 coordination 13 apposition 14 juxtaposition
Five providers participated in the construction of the corpus and its annotation. Intended to be highly heterogeneous, the corpus contains:
- newspaper articles
- literary and administrative texts
- oral transcriptions
- medical texts
- questions from past TREC and Amaryillis Questions Answering evaluation campaigns
An annotated example
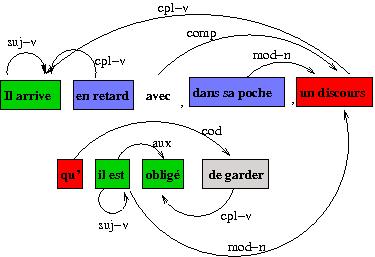
Annotation of the reference data was performed in two steps using simple HTML tools. The first table below shows an example of the first step: constituent annotation. Chunks of the same type are identified by the same color. The second table visualizes chunk numbering and words as well as chunk labels. It is used during for the second step: relation annotation. The last figure illustrates the corresponding annotation.
The annotated sentence is: Il arrive avec, dans sa poche, un discours qu'il est obligé de garder (a tentative translation might be : "He arrives with, in his pocket, a speech that he is obliged to keep there").

Evaluation
Annotations collected in HTML are transcribed in an XML format and all the participants map their parses into this unique format with which evaluation measures are taken. The evaluation measures adopted in EASY are the standard precision, recall and f-measure metrics computed both on constituents and dependencies. But the results are declined according to the different types of text material and according to the different syntactic phenomena annotated, in order to provide fine grained performance assessments. The following graphs illustrate the best results obtained for each of the three metrics (obtained by three different participants) computed for the dependencies.
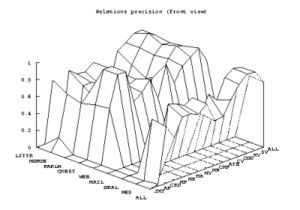
The different types of corpus are on the left: from literary (LITTR) at the background to medical (MED) corpus, and the complete corpus (ALL) at the foreground. The different dependencies are on the right: from JUXT (juxtaposition) at the foreground to SV (subject) and all of them (ALL), at the background.
The participant who obtains the best precision result doesn't parse oral corpus: it is the explanation of the "null values" in the middle of the graph. The best results are obtained for the relations subject, verb and noun modifiers, and are quite similar for the different types of corpus.
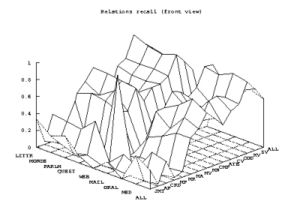
On the graph on the right, we see the best recall result obtained by another participant. The same global shape may be observed, with a "valley" for the oral result. The performances are quite similar for the literary, newspaper and parliament corpuses.
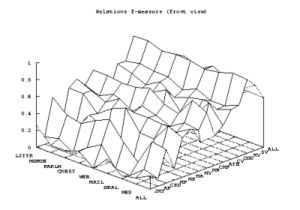
The third graph illustrates the best f-measure result obtained by a third parser. The differences between the different corpuses, and the different relations are not so different.
Results and prospects
EASY was launched in january 2003 and completed at the end of 2006, the results were presented at TALN 2007. The conclusions to draw from EASY are very positive:
- first of all, the number of participants is indicative of a strong synergy: 13 laboratories or companies submited their parser to the evaluation (making a total of 16 runs); among these we find: 7 research laboratories, 3 development and research institutes and 3 private companies.
- second, the principle of a common format in which all the participants could project their results seems to us a very positive point: even if some aspects of EASY annotation can be discussed, the existence of a common format is crucial to the users of parsing tools and developpers since it provides an exchange ground
- lastly, from the EASY evaluation campaign an evaluation package will be produced and made available to give the mean to perform easy benchmark tests.
- the efforts initiated in EASY continue in PASSAGE, a 3 year project supported by ANR (national research funding agency) whose aim is to use the EASY evaluation protocole to calibrate the automatic combination of the output of several parsers (starting with 6 systems from the EASY campaign) to produce very large corpus (several hundred million words) automatically annotated freely available.
References
- Paroubek, Patrick ; Vilnat, Anne ; Robba, Isabelle ; Ayache, Christelle : Les résultats de la campagne EASY d'évaluation des analyseurq syntaxiques du français, In Nabil Hathout and Philippe Muller, editors, Actes de TALN 2007 (Traitement automatique des langues naturelles), Toulouse, juin 2007. ATALA, IRIT.
- Paroubek, Patrick ; Robba, Isabelle ; Vilnat, Anne : EASY : la campage d'Évaluation des Analyseurs SYntaxiques, chapitre dans Le projet EVALDA, sous la direction de Stéphane Chaudiron, Hermès, à paraître