Gestural control of voice synthesis
S. Le Beux, C. d’Alessandro, B. Doval, A. Rilliard
Contents |
Abstract
Expressivity in voice synthesis can be seen on two main aspects : as a modification of the prosody or as a modification of the voice quality, i.e. mainly of the modification of the parameters of the glottis. Intonation synthesis using a hand-controlled interface is a new approach for effective synthesis of expressive prosody. A system for prosodic real time modification is described. The user is controlling prosody in real time by drawing contours on a graphic tablet while listening to the modified speech. This system, a pen controlled speech instrument, can be applied to text to speech synthesis which can be very effectively tuned by hands for expressive prosody synthesis. On the other hand, modification of vocal source parameters is not as straightforward. But relying on a signal processing model of the glottis such as LF [ref] or CALM [ref], we are able to study the effects of the modifications of its parameters on the vocal expressivity obtained. Here again, we present some experimentations of glottal source synthesis controlled by gestural devices. On the current state of development, we now use a joystick in conjunction with a graphic tablet to monitor this type of synthesis. The aim of this work is to obtain a global scheme for voice modification in order to be able to modify voice productions into a newly given vocal expression.
Introduction
As speech synthesizers attain acceptable intelligibility and naturalness, the problem of controlling prosodic nuances emerges. Expression is made of subtle variations (particularly prosodic variations) according to the context and to the situation. In daily life, vocal expressions of strong emotions like anger, fear or despair are rather the exception than the rule. Then a synthesis system should be able to deal with subtle continuous expressive variations rather than clear cut emotions. Expressive speech synthesis may be viewed from two sides: on the one hand is the question of expression specification (what is the suited expression in a particular situation?) and on the other hand is the question of expression realization (how is the specified expression actually implemented). The first problem (situation analysis and expression specification) is one of the most difficult problems for research in computational linguistics, because it involves deep understanding of the text and its context. In our framework, only the second problem is addressed. The goal is to modify speech synthesis in real time according to the gestures of a performer playing the role of a “speech conductor” [1]. The Speech Conductor adds expressivity to the speech flow using Text-to-Speech (TTS) synthesis, prosodic modification algorithms and gesture interpretation algorithms. This work is based on the hypothesis that human expressivity can be described in terms of movements or gestures, performed through different media, e.g. prosodic, body or facial movements. This question is closely related to musical synthesis, a field where computer based interfaces are still subject of much interest and development [2]. It is not the case for speech synthesis, where only a few interfaces are available for controlling in real time expressivity of spoken utterances. Existing gesture controlled interfaces for speech production either are dealing with singing synthesis (cf. [3], [4]) or with full speech synthesis [5], but with a sound quality level insufficient for dealing with expressivity. In this paper a new system for real-time control of intonation is presented, together with application to text- to-speech synthesis. This system maps hand gestures to the prosodic parameters, and thus allows the user to control prosody in a cross-modal way. As a by-product, the cross-modal approach of prosody generation represents a new way to generate and describe prosody and may therefore shed a new light on the fields of prosody systems and prosody description. In the same manner, a description of a synthesizer based on Causal-Anticausal Linear model is given. However, this particular one is not full Text-To-Speech system, whereas it mainly allows to synthesize vowels. But, the purpose is rather to concentrate our attention on voice quality parameters and their translations into expressivity. It can be seen as an Analysis-by-Synthesis way of investigating into expressivity.
Principle of the Controller
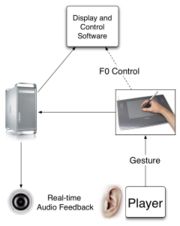
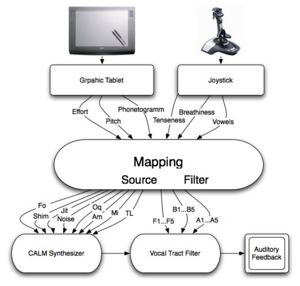
The real-time intonation controller operates in principle like a musical instrument. The loop between the player and the instrument is depicted in Figure 1. The player’s hand movements are captured using an interface, and these movements are mapped on the input controls of the synthesizer. The sound is modified accordingly, played, and this audio feedback is perceived by the player who modifies his gestures as a function of the perceived and intended sounds.
Writing Movements
Many devices, among which MIDI keyboard, Joystick and data glove, have been tested for capturing gestures with intonation control in mind. Keyboards are not well fitted because it allows only discrete scales, although in speech a continuous control is mandatory. An additional pitch-bend wheel proved not very convenient from an ergonomic point of view. As for the joystick and data glove, the precision in terms of position seemed insufficient: it proved too difficult to reach accurately a given target pitch. Such devices seem better suited for giving directions (as in a flight simulator) than precise values. We thus use a joystick for driving vocal dimensions such as breathiness and tenseness (see below). Moreover, the joystick we own features an 8-directions trigger that we use for navigating around the vocalic triangle. The graphic tablet has been chosen because it presents a number of advantages: its sampling frequency is high (200 Hz) and its resolution in terms of spatial position is sufficient for fine-grained parameter control (5080 dots per inches). Moreover, all the users are trained in writing since childhood, and are "naturally” very much skilled in pen position control. Scripture, like speech, is made of a linguistic content and a paralinguistic, expressive content. There is a remarkable analogy between pitch contour and scripture. This analogy between drawing and intonation is very effective and intuitive from a performance point of view. Untrained subjects proved to be surprisingly skilled for playing with intonation using the pen on the graphic tablet, even at the first trial. For intonation control, only one axis of the tablet is necessary. The vertical dimension (Y-axis) is mapped on the F0 scale, expressed in semi-tones. The x-scale is not used: it means that very different gestures can be used for realizing a same intonation pattern: some players were drawing circle like movements, when others preferred vertical lines or drawings similar to pitch contours. The second spatial dimension of the tablet will be used later for duration control in a second stage. Other degrees of freedom are still left in the tablet (pressure, switch) and can be used for controlling additional parameters, e.g. parameters related to voice quality. Taking these observations into account, we decided to opt for a Wacom graphic Tablet, A4 size and we based our platform on a Power PPC Apple G5 Mac, 2.3 GHz bi- processor. Our joystick is a Saitek CyberEvo.
"Calliphony" Real-Time Software
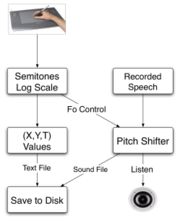
Real-time processing of information is a key point of the Calliphony system: as the user adapts his hand movement to perceived pitch at the output of the system, the delay has to remain inaudible. Calliphony is elaborated under the Max/MSP software ([6], [7]), which is a graphical development environment intended to process sound in real-time and which has already proven several years of reliable experience in real-time sound processing. Concerning the modification of speech pitch, we used a TD- PSOLA [8] Pitch-Shifter external provided by Tristan Jehan for Max/MSP environment [9]. As described on Figure 2, Calliphony takes as inputs the Y-axis position of the pen on the graphic tablet, and a recorded sound to be modified. It then maps the pitch value of the sound output to a value corresponding to the Y-axis value. This mapping is done on a logarithmic scale, such as the metric distance of each octave is the same. This corresponds analogously to the perception of the pitch by the human ear.
Glottal Source Real-Time Software
The software we developed for vocal source exploration is based on Causal-Anticausal Linear Model. For an explanation of the theory related to this model, please report to section 2 of this wiki (Go to page). In the net section, we will more specifically focus on the real-time implementation of this typical glottal source.
Instead of computing a causal version of the impulse response
off-line and then copying it backwards into a fixed buffer,
the computation is here straightforward. The iterative equation
corresponds indeed to the unstable anticausal filter. At any rate,
the explosion of the filter is avoided by stopping the computation
exactly at the Glottal Closure Instant (GCI). We can also note
that glottal flow and glottal flow derivative can both be achieved
with the same iterative equation, only changing the values of two
first samples used as initial conditions in the iteration process.
One other main implementation problem is that the straightforward
waveform generation has to be synchronised with the
standard Pure Data performing buffer size. This standard size is
64 samples which, at an audio rate of 44100Hz, corresponds to
a frequency of approximately 690 Hz. Most of the time, the fundamental
frequency of the glottal flow is less than 690 Hz, which
means that several buffers are necessary to achieve the complete
computation of one period. But whenever a buffer reaches the
end, the main performing routine is called and thus the values of
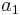 and
and 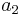 have to be frozen as long as the period time has not
been reached. A flag related to the opening of the glottis is then
introduced, fixed to the value of the period (in samples), and the
values of and are not changed until this flag is decreased
to 0. Once values of
have to be frozen as long as the period time has not
been reached. A flag related to the opening of the glottis is then
introduced, fixed to the value of the period (in samples), and the
values of and are not changed until this flag is decreased
to 0. Once values of 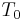 ,
, 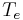 ,
,
,
, 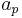 , and
, and 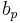 have been calculated
at the opening instant, only and have to be frozen, as these
are the only variables that are taken into account in the equations
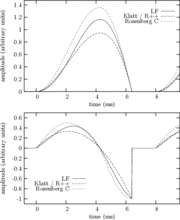
of the derivative glottal waveform. The different parameters of this model are detailed on Figure 3.
The various parameters of the model are then monitored by a graphic tablet and a joystick. The mapping function that are used for translating vocal dimensions to glottis and vocal tract parameters are described in the next section.
have been calculated
at the opening instant, only and have to be frozen, as these
are the only variables that are taken into account in the equations
of the derivative glottal waveform. The different parameters of this model are detailed on Figure 3.
The various parameters of the model are then monitored by a graphic tablet and a joystick. The mapping function that are used for translating vocal dimensions to glottis and vocal tract parameters are described in the next section.
Experiments and Evaluation
Prosody
Gestural Pitch Shifter
A dedicated system was developed in order to control the pitch of
speech utterances by means of handwriting gestures.
It deals with
two inputs:
- A recorded speech utterance with a flattened fundamental frequency (to e.g. 120Hz for a male speaker)
- The output of a gesture control device such as a graphic tablet.
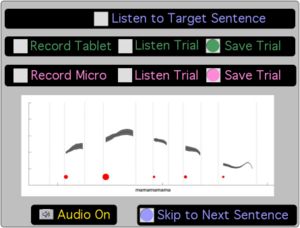
The value of one parameter of the graphic tablet (controlled by handwriting movements) is mapped to the pitch value of the spoken utterance, resulting in a direct control by the gesture of the output utterance pitch. Hence, this system allows one operator to precisely control the pitch of a previously recorded utterance, using only a pen on a graphic tablet. In order to test whether the control of prosody by handwriting movements can realistically reproduce natural prosody, a specific computer interface has been developed (cf. Figure 4) under the Max/MSP platform. It is intended to allow subjects of the experiment to imitate the prosody of natural speech either vocally or by handwriting movements. Each subject listens to a natural sentence by clicking on a button with the mouse pointer, and therefore has to imitate the prosody he has just heard by two means: vocally by recording his own voice, and by using the gestural controller of prosody. The interface displays some control buttons (cf. Figure 4):
- To record the voice or the graphic tablet imitation
- To replay the recorded imitations
- To save the satisfactory ones
It also displays a graphic representation of the prosodic parameters of the original sound, as it will be described latter. As the aim of the experiment is to investigate how close to the original the imitations can be, subjects are able to listen the original sound when they need to, and to perform imitation until they are satisfied. Several performances can be recorded for each original sound. Finally, subjects go on to the next sound. As the test typically lasts several minutes per sentence, subjects are instructed to take rest from time to time.
Prosodic Contours Measurements
All the sentences of the corpus were manually analyzed in
order to extract their prosodic parameters: fundamental
frequency (in semitones), syllabic duration, and intensity
thanks to Matlab (the yin script [11]) and Praat [10] programs.
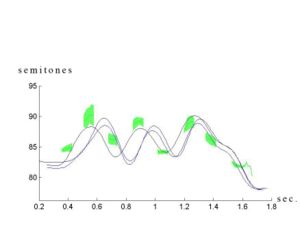
For all the sentences, graphics were displayed to depict the
prosody of original sound in order to facilitate the task of
subjects during the experiment (cf. Figure 3). These graphics
represents the smoothed 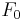 of the vocalic segments (manually
aligned), with the line thickness representing the voicing
strength. The voicing strength was calculated from the
intensity (in dB) of the signal at the point of analysis. The
locations of the Perceptual Centers [12] are represented by red
circles, the diameter of which is related to the mean intensity
of the vocalic segment. Vertical dotted lines represent the
phonemes’ boundaries.
of the vocalic segments (manually
aligned), with the line thickness representing the voicing
strength. The voicing strength was calculated from the
intensity (in dB) of the signal at the point of analysis. The
locations of the Perceptual Centers [12] are represented by red
circles, the diameter of which is related to the mean intensity
of the vocalic segment. Vertical dotted lines represent the
phonemes’ boundaries.
Prosodic Distances and Correlation
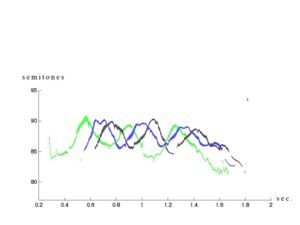
In order to evaluate the performance of the imitation (either
vocal or gestural), two physical measures of the distance
between the fundamental frequency extracted from the
imitation and the one from the original sentence were set of,
on the basis of the physical dissimilarity measures introduces
by Hermes [13]: the correlation between the two curves, and
the root-mean-square difference between theses two curves.
As already noted by Hermes, the correlation is a measure of
the similarity of the two sets of parameters, whereas the
RMS difference is a dissimilarity measure, but both give an
idea of the similarity of the compared curves. However,
correlation tests the similitude between the shapes of the two
curves, without taking into account their mean distances: e.g.
one can reproduce an curve an octave lower than the
original, if the shape is the same, the correlation will be very
high. On the contrary, the RMS distance will give an idea of
the area between the two curves, and is sensitive to differences
between the two mean levels.
Using a similar procedure as the one described in [13], the
two prosodic distances were applied with a weighting factor in
order to give more importance to the phonemes with a higher
sound level. The weighting factor used is the intensity, as a
measure of the local strength of voicing.
These two dissimilarity measures were automatically
calculated for all the gestural imitations recorded by the four
subjects for each of the 54 sentences. Then only the closest
gestural imitation (according to first the weighted correlation
and then the weighted RMS difference) was kept for the result
analysis.
This part of the work can be completely automated, as
there is no change in the duration of the output of the gestural
controller of speech (only is controlled). This is not the
case for the oral imitations, which have to be manually labeled
in order to calculate such distances. The distance computation
supposes segments of the same length, a condition not met for
vocal imitations. Therefore, only the distances between the
original sentences and the gestural imitations have been
calculated so far.
Graphics with the raw value of both the original and
the vocal imitations have been produced in order to visually
compare performances of gesture vs. vocal imitations.
Graphic with the stylized of the original sentences
(smoothed for the vocalic segments) superimposed with the
course of the pen on the graphic tablet were also produced in
order to compare the two imitations modalities (Figures 5 & 6).
Voice Quality
Dimensional Issues
Dimensional features of voice were first collected from various research fields (signal processing, acoustics, phonetics, singing), completed, and described in a formalised set [15, 16].
- Melody (F0): short-term and long-term elements involvedin the organisation of temporal structure of fundamental frequency
- Vocal Effort (V ): a representation of the amount of ”energy” involved in the creation of the vocal sound. It makes the clear difference between a spoken and a screamed voice for example [17, 18, 19, 20]
- Tenseness (T): a representation of the constriction of the voice source. It makes the difference between a lax and a tensed voice [21]
- Breathiness (B): a representation of the amount of air turbulence passing through the vocal tract, compared to the amount of voiced signal [21, 22]
- Mecanisms (Mi): voice quality modifications due to of phonation involved in sound production [23].
Description of Mapping functions
Once dimensions are defined, two main tasks can be investigated.
First, the implementation of mapping functions between
these dimensions and low-level parameters. Then, identification
and implementation of inter-dimensional phenomena. In
this area, many different theories have been proposed relating
to several intra or inter-dimensional aspects of voice production
[22, 20, 24, 25, 26, 27]. We decided to focus on some of them,
like direct implementation of tenseness and vocal effort, realisation
of a phonetogram, etc. and design our synthesis platform
in order to be easily extensible (e.g. to correct existing relations
and add new mapping functions etc.). All current parameters are
defined for a male voice.
Relations between Dimensions and Synthesis Parameters
We focused on several aspects of the dimensionnal process.
First, we consider relations between a limited number of dimensions
(, 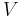 ,
, 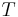 and
and 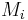 ) and synthesis parameters (
) and synthesis parameters (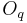 ,
, 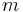 and
and
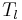 ). Then, we decided to achieve our data fusion scheme by
considering two different ”orthogonal” processes in the dimensionnal
control. On the one hand, vocal effort ( ) (also related
to variations, cf. next paragraph: Inter-Dimensionnal Relations)
and mecanisms () are controlling ”offset” values of
parameters (
). Then, we decided to achieve our data fusion scheme by
considering two different ”orthogonal” processes in the dimensionnal
control. On the one hand, vocal effort ( ) (also related
to variations, cf. next paragraph: Inter-Dimensionnal Relations)
and mecanisms () are controlling ”offset” values of
parameters (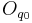 ,
, 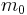 ,
, 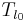 ). On the other hand, tenseness ()
controls ”delta” values of and around their offsets ( , ). Considering this approach, effective values of synthesis
parameters can be described as:
). On the other hand, tenseness ()
controls ”delta” values of and around their offsets ( , ). Considering this approach, effective values of synthesis
parameters can be described as:
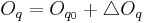
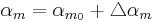
Following equations consider and parameters normalized between 0 and 1 and representing the ith phonation mecanism.
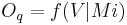
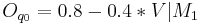
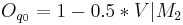
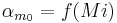
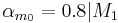
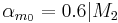
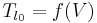
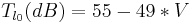
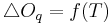
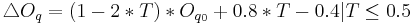
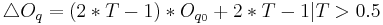

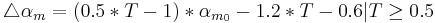
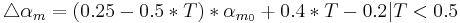
Concerning the vowels parameters (Formants, Bandwiths, Amplitudes), these are just retrieved and interpolated from tables given by analyses of real speech. Concerning Jitter and Shimmer, random values are generated respectively around instantaneous frequency and amplitude. Finally, a pulse noise is added to give more natural to the voice. This noise is pulsed by the glottal waveform.
Results
Prosody
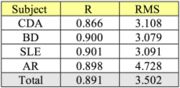
- Effect of Subjects
There is no important difference between the results obtained
by all subjects: all correlations are comparable and around 0.9,
showing that subjects are able to perceive and reproduce the
shape of the intonation curve by means of handwriting
movement. The only noticeable difference is the RMS
distance obtained by subject AR (4.7) compared to the score
of other subjects (around 3.1). This difference indicates an
curve closer to the original one for the three other subjects
than for AR. This can be explained by the fact that AR is the
only subject without a musical education, and therefore
not trained to reproduce a given melody as the others are.
However, as the correlations are quite the same, it does not
imply difficulty to reproduce the pitch variation, but only the
pitch height.
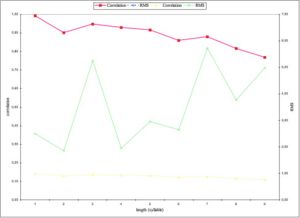
- Effect of Sentence Length
The sentence length has a more noticeable effect on the distances. As shown in the Figure 9, the dissimilarity measures increase as the sentences length grows: correlation (red) continuously decrease when sentence length increase, and except for some accident for the 3 and 7-syllable length sentences, RMS (green) difference grows according to sentence length. The two accidents could be explained by high RMS distances obtained by two subjects for this stimulus, and by the fact that this measure is particularly sensitive to small differences between curves. The effect of sentence length could be an artifact, because computation of correlation does not take into account any weighting for length compensation. More analyses would be needed before concluding on a sentence length effect.
- Effect of Prosodic Style
Declarative, emphasized or interrogative sentence modalities
give similar results according to the correlation measure, but
RMS distance is smaller for declarative curves (2.0) than for
emphasized or interrogative ones (respectively 4.2 and 4.4). It
can be linked to the preceding result: subjects are able to
reproduce the shape of all intonation contours, but the precise
perception of the pitch level is harder when the curve present a
glissando (e.g. during emphasis or interrogation) than a more
flat curve, like for declarative intonation.
Finally, imitating a reiterant sentence is nor easier nor
harder than to imitate a lexicalized one: distances are the same
for both kinds of stimuli.
Voice Quality
Several vocal instruments have been implemented for singing synthesis [1] [15], but no real evaluation has been made so far. We are currently focusing more specifically on production of various vocal expression in speech, and we expect being able to synthesize japanese expression. This future work is actually in relationship with the work done by T.Shochi, V. Aubergé & A. Rilliard (Go to page)
Discussion and Conclusion
- Performance Level and Feasability
Good performance levels are achieved in terms of correlation and distances between original and reiterated intonation contours. Of course, it must be pointed out that the best reiterated utterance has been selected for each sentence. However, the amount of training of each subject was not very heavy. The task seemed not particularly difficult, at least compared to other intonation recognition tasks, like e.g. musical dictation.
- Gestural and Vocal Modalities
A remarkable and somewhat striking result is that the performance levels reached by hand written and vocal reiterated intonation are very comparable. This could suggest that intonation, both on the perceptual and motor production aspects, is processed at a relatively abstract cognitive level, as it seems somehow independent of the modality actually used. This fact was already inferred by orators in the ancient world, because description of the expressive effect of co-verbal gestures (i.e. multimodal expressive speech) has been remarked even in early roman rhetoric treatises [14]. Then one can hypothesize that intonation control can be achieved by other gestures than pitch gestures with comparable accuracy.
- Intonation and Gestures
It seems that micro-prosodic variations have been neglected for almost all sentences. Writing is generally slower than speaking, and then hand gestures are not able to follows fine grained intonation details like micro-prosody [5]. Moreover, results for delexicalized speech and normal speech are comparable, although micro-prosody is almost neutralized in delexicalized speech. Then the hand gestures correspond rather to prosodic intonation movements. The specific gestures used by different subjects for achieving the task at hand have not been analyzed in great detail for the moment. Some subject used rather circular movements, other rather linear movements. This point will be addressed in future work.
Conclusion and Perspectives
This paper presents a first evaluation of computerized chironomy, i.e. hand-driven intonation control. The results show that vocal intonation reiteration and chironomic intonation reiteration give comparable intonation contours in terms of correlation and RMS distance. Applications and implications of these finding are manifold. Chironomic control can be applied to expressive speech synthesis. It can also be used for expressive speech analysis, as expressive contours can be produced and represented by the hand-made tracings. Future work will address the question of gesture control of rhythm and voice quality parameters. An auditory evaluation of the reiterated intonation contours is also planned. Finally, this work can also serve as a basis for intonation modeling in terms of movements. This could form a unified framework for expressive gesture representation, using common features like velocity, target position, rhythmic patterns etc. Moreover, in combination with voice quality modification, this framework would provide us with a powerful tool for global expressive modification and synthesis.
References
[1] d'Alessandro, C., et al. (2005) "The speech conductor : gestural control of speech synthesis." in eNTERFACE 2005. The SIMILAR NoE Summer Workshop on Multimodal Interfaces, Mons, Belgium.
[2] NIME Conference homepage (2007). Online proceedings available at: http://www.nime.org (Accessed: 21 Sept. 2007)
[3] Cook, P., (2005) "Real-Time Performance Controllers for Synthesized Singing" Proc. NIME Conference, 236_237, Vancouver, Canada.
[4] Kessous, L. , (2004) "Gestural Control of Singing Voice, a Musical Instrument". Proc. of Sound and Music Computing, Paris.
[5] Fels, S. & Hinton, G. , (1998) “Glove-Talk II: A Neural Network Interface which Maps Gestures to Parallel Formant Speech Synthesizer Controls.” IEEE Transactions on Neural Networks, 9 (1), 205_212.
[6] Puckette, M. (1991). “Combining Event and Signal Processing in the MAX Graphical Programming Environment”. Computer Music Journal 15(3): 68-77.
[7] Cycling'74 Company (2007) Max/MSP Software. Available at: http://www.cycling74.com/ (Accessed: 21 Sept. 2007)
[8] E. Moulines and F. Charpentier, (1990) "Pitch- synchronous waveform processing techniques for text-to-speech synthesis using diphones," Speech Communication, vol. 9, pp. 453–467.
[9] Jehan, T. Max/MSP Externals. Available at: http://web.media.mit.edu/~tristan/ (Accessed: 21 Sept. 2007)
[10] Boersma, P. & Weenink, D. (2006) "Praat: doing phonetics by computer" (Version 4.5.05) [Computer program]. Retrieved 12/2006 from http://www.praat.org/
[11] de Cheveigné, A. & Kawahara, H. (2002). “YIN, a fundamental frequency estimator for speech and music”. JASA, 111, 1917-1930.
[12] Scott, S.K. (1993). "P-Centers in speech – an acoustic analysis." PhD thesis, University College London.
[13] Hermes, D.J. (1998). “Measuring the Perceptual Similarity of Pitch Contours”. J. Speech, Language, and Hearing Research, 41, 73-82.
[14] Tarling, J. (2004). “The Weapons of Rethoric”, Corda Music, Pub. London.
[15] N. D’Alessandro, C. d’Alessandro, S. Le Beux, and B. Doval, “Realtime CALM Synthesizer, New Approaches in Hands-Controlled Voice Synthesis”, in NIME’06, 6th international conference on New Interfaces for Musical Expression, (IRCAM, Paris, France), pp. 266–271, 2006.
[16] C. d’Alessandro, N. D’Alessandro, S. Le Beux, and B. Doval, “Comparing Time-Domain and Spectral- Domain Voice Source Models for Gesture Controlled Vocal Instruments”, in Proc. of the 5th International Conference on Voice Physiology and Biomechanics, 2006.
[17] R. Schulman, “Articulatory dynamics of loud and normal speech”, J. Acous. Soc. Am., vol. 85, no. 1, pp. 295–312, 1989.
[18] H. M. Hanson, "Glottal characteristics of female speakers" Ph.d. thesis, Harvard University, 1995.
[19] H. M. Hanson, “Glottal characteristics of female speakers : Acoustic correlates”, J. Acous. Soc. Am., vol. 101, pp. 466–481, 1997.
[20] H. M. Hanson and E. S. Chuang, “Glottal characteristics of male speakers : Acoustic correlates and comparison with female data”, J. Acous. Soc. Am., vol. 106, no. 2, pp. 1064– 1077, 1999.
[21] N. Henrich, "Etude de la source glottique en voix parlée et chantée" Ph.d. thesis, Université Paris 6, France, 2001.
[22] D. Klatt and L. Klatt, “Analysis, synthesis, and perception of voice quality variations among female and male talkers”, J. Acous. Soc. Am., vol. 87, no. 2, pp. 820–857, 1990.
[23] M. Castellengo, B. Roubeau, and C. Valette, “Study of the acoustical phenomena characteristic of the transition between chest voice and falsetto”, in Proc. SMAC 83, vol. 1, (Stockholm, Sweden), pp. 113–23, July 1983.
[24] P. Alku and E. Vilkman, “A comparison of glottal voice source quantification parameters in breathy, normal and pressed phonation of female and male speakers”, Folia Phoniatr., vol. 48, pp. 240–54, 1996.
[25] H. Traunmüller and A. Eriksson, “Acoustic effects of variation in vocal effort by men, women, and children”, J. Acous. Soc. Am., vol. 107, no. 6, pp. 3438–51, 2000.
[26] N. Henrich, C. d’Alessandro, B. Doval, and M. Castellengo, “On the use of the derivative of electroglottographic signals for characterization of non-pathological phonation”, J. Acous. Soc. Am., vol. 115, pp. 1321–1332, Mar. 2004.
[27] N. Henrich, C. d’Alessandro, M. Castellengo, and B. Doval, “Glottal open quotient in singing: Measurements and correlation with laryngeal mechanisms, vocal intensity, and fundamental frequency”, J. Acous. Soc. Am., vol. 117, pp. 1417–1430, Mar. 2005.