Statistical Machine Translation
Holger Schwenk Daniel Déchelotte Hélène Maynard Alexandre Allauzen Gilles Adda
Contents |
Object
This article summarizes our research on the development of state-of-the-art statistical machine translation systems for several language pairs. Our systems are based on the freely available decoder Moses and extensions developed at LIMSI, in particular a two pass decoding strategy and a continuous space language model. We also report on ongoing work on the integration of linguistic knowledge into the translation model.
Description
Automatic machine translation was one of the first natural language processing applications investigated in computer science. From the pioneer works to today's research, many paradigms have been explored, for instance rule-based, example-based, knowledge-based and statistical approaches to machine translation. Statistical machine translation (SMT) seems today to be the preferred approach of many industrial and academic research laboratories.
The goal of statistical machine translation is to produce a target sentence E from a source sentence F that maximizes the posterior probability:
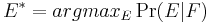
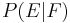 is not modeled directly, but
decomposed into several feature functions, among them several translation
models, a distortion or reordering model and a language model
is not modeled directly, but
decomposed into several feature functions, among them several translation
models, a distortion or reordering model and a language model 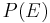 of the target
language. The basic units of the translation model are so called phrases, i.e.
groups of words that should be translated together.
of the target
language. The basic units of the translation model are so called phrases, i.e.
groups of words that should be translated together.
All the models can be trained automatically from parallel texts, i.e. texts in the source and target language that are aligned at the sentence level. Target-to-source and source-to-target word alignments are first built with the freely available tool Giza++. These alignments are then used to extract phrases and to calculate various scores the will be used during decoding.
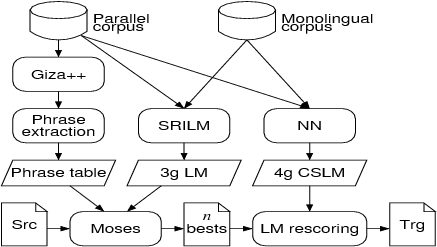
LIMSI's SMT system employs a two-pass strategy which is summarized in Figure 1. In the first pass, the public decoder Moses generates 1000-best lists with a 3-gram back-off language model. In the second pass, the n-best lists are rescored with a 4-gram back-off or continuous space language model and the final hypothesis is then extracted.
Continuous space language models
Often, there is only a limited amount of in-domain language model training data available. Therefore, we propose to use the so-called continuous space language model that is expected to take better advantage of the available training data. The basic idea of this approach is to project the word indices onto a continuous space and to use a probability estimator operating on this space. Since the resulting probability functions are smooth functions of the word representation, better generalization to unknown n-grams can be expected. A neural network can be used to simultaneously learn the projection of the words onto the continuous space and to estimate the n-gram probabilities. This is still a n-gram approach, but the language model posterior probabilities are interpolated for any possible context of length n-1 instead of backing-off to shorter contexts.
This approach was previously applied to large vocabulary continuous speech recognition. As shown in the next section, it also achieves significant improvements in a SMT system.
Results
The following experiments were carried out in the framework of the Tc-star project, which is envisaged as a long-term effort to advance research in all core technologies for speech-to-speech translation. The task considered is the translation of the summaries of the European Parliament Plenary Sessions between English and Spanish. Research on the translation of automatically recognized speech is summarized in an another page.
About 1.2M sentences of parallel texts are provided (roughly 36M words). Additional monolingual data was used to train the target language models. The results on development and test data are summarized in Table 1. The numbers in the column Eval07 correspond to the official scores obtained in an international evaluation performed in February 2007. Our system achieved the best result when translating from English to Spanish and the third rank for the opposite translation direction.
| Translation | Dev06 | Eval06 | Eval07 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| units | 3g | 4g | CSLM | 3g | 4g | CSLM | 3g | 4g | CSLM | |
| Spanish/English | words | 47.20 | 47.64 | 48.26 | 50.96 | 51.23 | 51.66 | 48.42 | 48.67 | 49.19 |
| English/Spanish | words | 48.78 | 49.39 | 50.15 | 48.38 | 49.06 | 50.20 | 49.19 | 50.17 | 51.04 |
| enriched | 48.92 | 49.45 | 50.30 | 48.71 | 49.00 | 49.96 | 49.13 | 49.91 | 51.04 | |
Enrichment with syntactical information
It is well-known that syntactic structures vary greatly across languages. Spanish, for example, can be considered as a highly inflectional language, whereas inflection plays only a marginal role in English. Part-of-speech (POS) language models can be used to rerank translation hypotheses, but this requires tagging the n-best lists generated by the SMT system. This can be difficult since POS taggers are not trained for ill-formed or incorrect sentences. Finding a method in which morpho-syntactic information is used directly in the translation model could help overcome this drawback but also account for the syntactic specificities of both source and target languages. Therefore, we investigate a translation model which enriches every word with its syntactic category, resulting in a sort of word disambiguation. The enriched translation units are a combination of the original word and the POS tag. The translation system takes a sequence of enriched units as inputs and outputs. This implies that the test data must be POS tagged before translation. Likewise, the POS tags in the enriched output are removed at the end of the process to provide the final translation hypothesis. This approach also gives the flexibility to rescore the $n$-best lists using either a word language model, a POS language model or a language model of enriched units.
Lexical disambiguation based on POS information has only been applied when translating from English to Spanish. The results are summarized in the last line of Table 1. Although small improvements may be observed on the development data, they do not carry over to the test data. Still, it can be noticed that the enriched unit system always outperforms the baseline word system after the first pass; but there is no significant difference after rescoring the n-best lists with the continuous space language model. We conjecture that both approaches correct the same translation problems. Some limited human evaluation has however shown that the lexical disambiguation seems to produce sentences with better syntax and semantics.
French/English System
The same approach was also applied to build a statistical machine translation system between English and French. This system participated in an international evaluation organized in conjunction with the ACL workshop on Statistical machine translation in June 2007. It obtained very good rankings in comparison to other SMT systems and commercial systems, with respect to automatic measures like the BLEU score as well as in an human evaluation.
References
[1] D. Déchelotte, H. Schwenk, H. Bonneau-Maynard, A. Allauzen et G. Adda, A state-of-the-art Statistical Machine Translation System based on Moses, In MT Summit, pages 127-133, September 2007.
[2] H. Schwenk, Building a Statistical Machine Translation System for French using the Europarl Corpus, In ACL workshop on Statistical machine translation, pages 189-192, June 2007.
[3] H. Schwenk, D. Déchelotte, H. Bonneau-Maynard, and A. Allauzen, Modeles statistiques enrichis par la syntaxe pour la traduction automatique, in Traitement du Langage Naturel, pages 253-262, June 2007.
[4] H. Bonneau-Maynard, A. Allauzen, D. Déchelotte, and H. Schwenk, Combining morphosyntactic enriched representation with n-best reranking in statistical translation, in HLT/NACL workshop on Syntax and Structure in Statistical Translation, pages 65-71, April 2007.