Arabic Broadcast Transcription
A. Messaoudi L. Lamel J.L. Gauvain
Contents |
Object
This research aims at improving the acoustic, pronunciation and language models taking into account specificities of the Arabic language. Since Arabic texts and audio transcripts are almost exclusively non-vocalized, the training methods have to overcome this missing data problem. In order to facilitate training on Arabic audio data with non-vocalized transcripts a generic vowel model has been introduced.
Description
Research is underway to improve all aspects of the models used in the LIMSI Arabic system, with a recent focus on improving the acoustic and pronunciation models. Previous work has shown that modeling short vowels in Arabic can significantly improve performance even when producing a non-vocalized transcript.
While pronunciation generation in Arabic from vocalized texts is often considered straightforward there are several contexts that modify the pronunciations, and it can be important to explicitly represent some pronunciation variants. One of the frequent variants is the pronunciation of the definite article 'Al' ('the'). When the 'Al' precedes a lunar consonant it is usually pronounced as /al/. When the 'Al' precedes a solar consonant it is usually silent, but transforms the following consonant into a geminate (the consonant is 'doubled'). Generally speaking all of the Arabic consonants can occur as singletons or geminates. The 'tanwin' is another grammatical mark which specifies that that noun is to be intended non-definite. The tanwin causes short vowels in word final position to be 'doubled', which is phonetically realized as adding an 'n' after the final vowel (also referred to as nunation). These studies aim to improve the acoustic and lexical models by explicitly representing the gemination and tanwin.
Generally speaking, extending the pronunciation dictionary to include entries for additional training data entails some manual intervention or verification. For Arabic, the main difficulty lies in determining the vocalized forms for the new words. A generic vowel was introduced to handle words unable to be processed by the Buckwalter morphological analyzer (typically proper names, technical words, words in Arabic dialects). A set of rules generates multiple pronunciations for each word represented with consonants, long vowels, and the generic vowel. Since vowels may also be absent (written with a Sukoun), additional pronunciations are added by removing one generic vowel at a time.
| Graphemic form | Generic Pronunciation |
| ktb | k@t@b@ k@t@b@n |
| extended | k@t@b@ k@t@b@n kt@b@ kt@b@n k@tb@ k@tb@n k@t@b |
One obvious way to improve the acoustic models is to train them on more data. Since untranscribed data are easily available, we make use of unsupervised methods to train with these [Lamel, Gauvain, Adda 2002].
Results
Modeling Geminates and Tanwin
The original phone set contains 37 symbols: 28 Arabic consonants, 3 foreign consonants, 6 vowels (i,a,u short and long). When pronunciations are determined with this phone set, all consonants with a gemination mark were simply doubled. While this may be a reasonable approximation for some sounds, such as fricatives, if is clearly not well adapted to plosives where gemination does not result in multiple bursts. An additional 30 phone symbols were added to represent the geminate phones.
Table 1. Word error rates without and with explicit modeling of geminates on the GALE 2000 development data sets. bnat06: broadcast news, bcat06: broadcast conversations.
| Model | bnat06 | bcat06 |
| Standard model | 22.0% | 32.6% |
| Geminate model | 21.7% | 32.3% |
| Combination | 21.5% | 31.9% |
Pronunciation Variants
An error analysis on the bnat06 data was carried out for data the Arabic system evaluated in the GALE 2006 evaluation. The main source of errors involves the insertion or deletion of a prefix or a suffix, such as the confusion of ktAb/wktAb or ktAbh/ktAb. The article 'Al' is found in 37% of the prefix errors (many prefixes end in Al), and contributes an absolute error of 1%. In examining the errors a number of dialectal pronunciation variants were observed, that were not represented in the lexicon. Figure 1 shows two spectrograms of the word 'aljalsa (meeting). The final short vowel in the example on the left is an /a/. The right example is the same word, but the final vowel is not produced in the same manner. Arabic speakers consider this to be an /i/, whereas it appears more like an /e/ in the spectrogram,
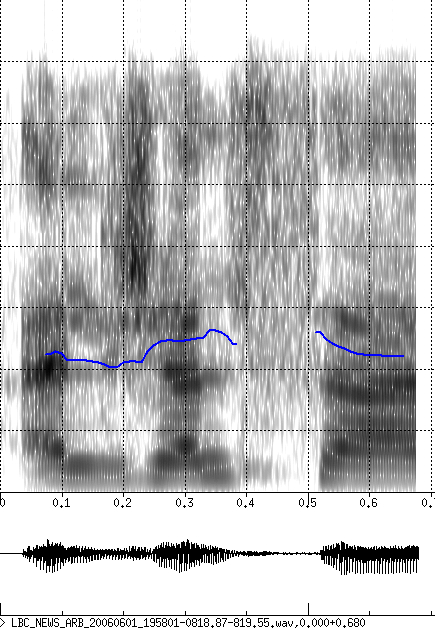
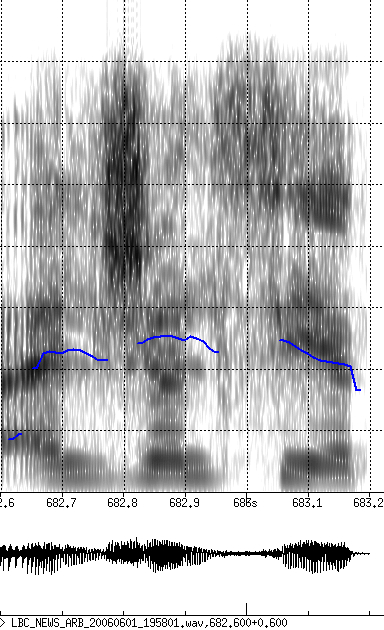
Figure 1: Example spectrograms of the word 'aljalsa (meeting)
illustrating the Lebanese realization of the final vowel.]
Alternative variants were systematically added to the pronunciation lexicon, and an absolute performance improvement of 0.3% was obtained on the broadcast news dev data and 0.6% on the broadcast conversation dev data.
Duration Modeling
It is well known that HMMs are not properly modeling the phone and the word durations. The segment duration being implicitly encoded in the model topology, the transition probabilities, and the derivative features, none of these model parameters can properly capture segment duration when considering a wider context than a triphone. The adopted strategy is to add duration information as a post-processing of the decoding process, but instead of applying such post-processing to an N-best list as it often done, here a word lattice representation which also includes the phone segmentation for each word edge is used. This approach allows duration information to be used in conjunction with consensus decoding as proposed in Jennequin and J.L. Gauvain (2007). Recognition results with the best Arabic system configuration are given without and with the duration model in Table 2, where the duration model is seen to give 0.2-0.4% absolute gain on the GALE development data.
Table 2. Word error rates on GALE broadcast news (bnat06) and broadcast conversation (bcat06) development data with and without the duration model.
| Model | bnat06 | bcat06 |
| Standard model | 19.7% | 28.5% |
| + Duration model | 19.5% | 28.1% |
References
J.L. Gauvain, L. Lamel, G. Adda, The LIMSI Broadcast News Transcription System, Speech Communication, 7(1-2):89-108, May 2002.
L. Lamel, J.L. Gauvain, G. Adda, Lightly Supervised and Unsupervised Acoustic Model Training, Computer, Speech and Language, 16(1):115-229, January 2002.
A. Messaoudi, J.L. Gauvain, L. Lamel, Arabic Broadcast News Transcription using a One Million Word Vocalized Vocabulary, IEEE ICASSP'06, I-1093-1096, Toulouse, May 2006.
L. Lamel, A. Messaoudi, J.L. Gauvain, Improved Acoustic Modeling for Transcribing Arabic Broadcast Data, ISCA Interspeech'07, Antwerp, Aug 2007.
N. Jennequin and J.L. Gauvain, `Modeling Duration Via Lattice Rescoring , ICASSP-07, Honolulu, April 2007.