3D Audiovisual Rendering and Real-Time Interactive Control of Expressivity in a Talking Head
J-C Martin C. d'Alessandro, C. Jacquemin, B. Katz, S. Lebeux, A. Max, L. Pointal, A. Rilliard, M., Noisternig, M. Courgeon
Contents |
Film
Object
Current applications of talking heads are mostly designed for desktop configurations. Mixed and virtual reality applications call for coordinated and interactive spatial 3D rendering in the audio and visual modalities. For example, the rendering of the movements of a virtual character in a virtual scene (locomotion of the character or rotation of its head) and the spatial and orientation dependent audio rendering in 3D of the synthetic speech during these movements need to be coordinated (Figure 1). Furthermore, the expressiveness of the agent in the two modalities needs to be displayed appropriately for effective affective interactions, and combined with audiovisual speech. This requires experimental investigations on how to control this expressiveness and how it is perceived by users. These applications and experiments raise several requirements: spatial coordination (3D orientation + distance) of spatially rendered speech and head display, real-time adaptation of expressive audiovisual signals to user’s actions, and face models at different levels of details for different applications.

Description
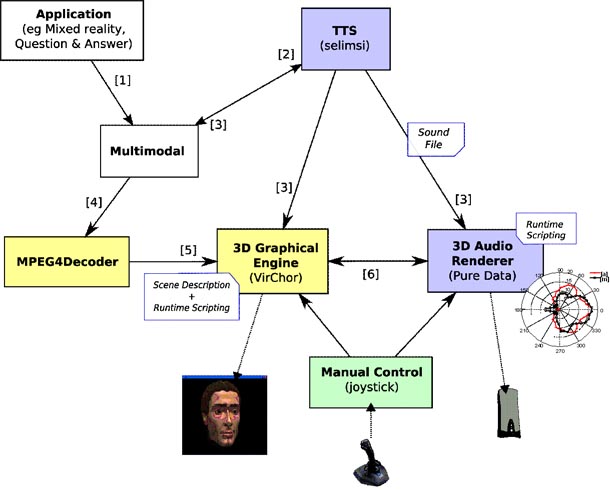
The following components have been integrated in a platform that can be used for perceptual experiments and future development of mixed reality applications (Figure 2):
- Real time synthesis and 3D rendering of expressive speech
- Selection and concatenation of non-uniform units in a corpus (Prudon & d’Alessandro 01)
- New model of phoneme-dependent human speech directivity patterns (Katz et al. 06, Kob & Jers 99)
- 3D real time rendering of facial expressions using a GPU-based 3D graphic engine (VirChor)
- Real-time interactive facial animation (GPU 10x faster CPU)
- In CPU, VirChor produces 2 channels (speech and expressions) using keyframe sequences
- GPU animation involves a vertex shader and a fragment shader
- MPEG4 model exported / edited from Poser & Xface
- Visemes refined manually from a video corpus (1 viseme = 1 phoneme in context (Benoit et al. 92))
- Animated wrinkles: bump mapping and GPU rendering
- Going pale or red: multilayer skin model
- Interactive control via gesture input
- Enables to demonstrate subtle variations of expression via on-line interaction
- Gestural control of speech expressive signals (d’Alessandro et al. 05)
- Gestural control of facial expression of emotion (Courgeon et al. In prep)
Results and prospect
The current state of the platform enables one to conduct an experimental study about perception of facial expression of emotion and personality traits. Currently there is no co-articulation model since the focus of the research is on 3D and real time interaction. An evaluation test was done with the graphical display (Jacquemin 07). Future directions include the definition of several head models, the management of interruption and the synchronization of graphics and audio, and finally, the connection with various applications such as a cooperative Q&A system (Ritel) and interactive arts applications.
References
- d'Alessandro, C., D'Alessandro, N., Le Beux, S., Simko, J., Cetin, F., Pirker, H.: The speech conductor : gestural control of speech synthesis. eNTERFACE 2005. The SIMILAR NoE Summer Workshop on Multimodal Interfaces (2005) Mons, Belgium 52-61
- Buisine, S. and Martin, J. C. (2007). "The effects of speech-gesture cooperation in animated agents’ behavior in multimedia presentations." International Journal "Interacting with Computers: The interdisciplinary journal of Human-Computer Interaction". Elsevier. 19: 484-493.
- Jacquemin, C.: Pogany: A tangible cephalomorphic interface for expressive facial animation. 2nd International Conference on Affective Computing and Intelligent Interaction (ACII 2007) (2007) Lisbon, Portugal
- Jacquemin, C. (2007). Headshaped tangible interface for affective expression. In Proceedings, 21st British HCI Group Annual Conference, HCI '2007, Lancaster, UK.
- Kob, M., Jers, H.: Directivity measurement of a singer. Journal of the Acoustical Society of America 105 2 (1999)
- Katz, B., Prezat, F., d'Alessandro, C.: Human voice phoneme directivity pattern measurements. 4th Joint Meeting of the Acoustical Society of America and the Acoustical Society of Japan (2006) Honolulu, Hawaii.
- Le Beux, S., Rilliard, A., d’Alessandro, C.: Calliphony: A real-time intonation controller for expressive speech synthesis. 6th ISCA Workshop on Speech Synthesis (SSW-6) (2007) Bonn, Germany
- Martin, J.-C., d’Alessandro, C., Jacquemin, C., Katz, B., Max, A., Pointal, L. and Rilliard, A. (2007). 3D Audiovisual Rendering and Real-Time Interactive Control of Expressivity in a Talking Head 7th International Conference on Intelligent Virtual Agents (IVA'2007). Paris, France September 17-19.
- Martin, J.-C., Jacquemin, C., Pointal, L., Katz, B., d'Alessandro, C., Max, A. and Courgeon, M. (2007). A 3D Audio-Visual Animated Agent for Expressive Conversational Question Answering. International Conference on Auditory-Visual Speech Processing (AVSP'2007). Hilvarenbeek, The Netherlands August 31 - September 3. .PDF Poster
- Prudon, R., d'Alessandro, C.: A selection/concatenation text-to-speech synthesis system: databases development, system design, comparative evaluation. 4th ISCA/IEEE International Workshop on Speech Synthesis (2001)
- Rosset, S., Galibert, O., Illouz, G., Max, A.: Integrating spoken dialog and question answering: the Ritel project. Interspeech'06 (2006) Pittsburgh, USA