Natural Language Processing for Authoring Aids
Aurélien Max, Sammy Debbagi
Contents |
Context
Authoring aids can strongly influence the way people write (Piolat et al., 1993). For many, word processors are the de facto tools for writing on modern computers, and hence have become the most spread authoring aids. Surprisingly, the assistance they provide to their user mostly concentrates on layout and shallow text issues. Another authoring approach uses annotation languages for ensuring a clear separation between content and layout, which clearly suits some professional needs, and can even be extended to producing highly constrained documents (Hartley et Paris, 1997 ; Max, 2007). But while it is not clear whether using XML-based annotation languages actually helps writers overall, it certainly brings new constraints on a task that is already highly difficult.
Some researchers advocate that writers should be given more help in describing the content of their documents and in organizing them into well-formed document plans. Various approaches, ranging from diagrammatic representations of ideas to ontology construction, can provide efficient assistance in this area to a certain extent. A tight integration between content and text assistance modules within writing aids is likely to provide tools that will better assist in document authoring. Some such tools have already been built (e.g. (Esposito, 2003)), but with a tendency to help in content structuring first by means of diagrams, and not offering clear means to go back and forth between content and realization. Studies show that there exists a close interaction between ideas and the construction of a document plan, in which both ideas and the plan can modify each other (Zock, 1986). In fact, the process of writing includes adaptations at the conceptual level (addition or suppression of ideas) and at the textual level (modification of the document plan). The following hypotheses can be made: the messages that make up a document plan are not statically assembled into a final plan but they are dynamically added to a temporary plan, and candidate plans can be produced using various features of the messages depending on which factors are to be privileged.
Moreover, some processing techniques which have been researched for years in the the Natural Language Processing community may be considered for inclusion in what may be called language-sensitive text editors (Dale et Douglas, 1996). Commercial tools already offer grammatical checkers, and the most recent ones start proposing help of a shallow semantic kind (e.g. (Antidote RX ; Cordial ; Prolexis)). The inevitable appearance of false alerts within the reported errors and the nature of the assistance that can be provided at various levels call for a nonpreemptive assistance from the machine, which can detect certain errors and possible errors, and more generally assist the user in organizing her various authoring tasks more efficiently.
Towards language- and content-sensitive authoring workbenches
We believe that there is an important gap to be filled in providing computer tools that will better support writers' tasks. Observations from writers needs and habits can provide interesting clues in how this can be achieved. Scientific writers, for example, can produce an important quantity of documents, each referring to common ideas that can be expressed and articulated in different ways to conform to constraints on language (natural language and style), technicality, conciseness, and of course layout. Many ideas will preexist the creation of a document (e.g. internal report, theses, conference papers, etc.), but some can appear as the result of document creation, and in turn have an impact on ideas. Ideas can, in the extreme, be specified and organized completely independently of them being used in documents. Documents, in turn, could refer to prespecified ideas, but this does not need to be. What seems important is to allow authors to go back and forth between what may be called the conceptual space and the textual space. Moreover, the collaborative trend of authoring, well exemplified by the widespread adoption of wiki-related technologies, should be taken into account, which implies that textual spaces and even conceptual spaces could be shared between contributors.
Apart from human authoring issues, document processing can appear to be highly counter-productive, translation being the most patent example. Documents need to be written before they are translated, and each revision on source documents requires reworking on the various translations (it could be noted that the answer from the industry to this issue included using controlled languages for technical documents, putting yet more constraints on the writers' work). From the author's viewpoint, the localization of a document for a given community can often appear as just a set of parameter (providing the author can write in foreign languages). In the extreme, controlled authoring approaches (Hartley and Paris, 1997 ; Max, 2007) can help authors produce multilingual versions of their documents with the help of a natural language generator from document content representations.
More generally, for documents on any domain, an authoring workbench should help create and organize metadata on ideas and document parts, so that the produced documents are literally enriched (an extreme view on this is that of self-explaining documents (Blanchon and Boitet, 2006)). However, it seems very important that the use of these features remain optional as long as authors believe they do not need them. Applications include semantic indexing for the Semantic Web, multilingual document production, and document personalization (e.g. produce documents for language-impaired readers (Max, 2006) or for a non-technical audience).
Lastly, some features involving Information Retrieval and Natural Language Processing techniques can be made available to writers within such a workbench:
- search within conceptual and textual spaces, based on text and/or annotations, which can help locate ideas or text spans, detect redundancy on content and form (or plagiarism in the extreme)
- checkers for conformity to genres and usages and for grammaticality and comprehensibility
- document structuring assistant, based on idea network exports and linking or text discourse segmentation
- authoring organization assistant
Results and prospects
In order to assess the interest of companies and researchers on the issues of computerized authoring aids, we organized an ATALA meeting in June 2006 (Hernandez et al., 2006). Speakers from the industry claimed that authoring aid should resemble as much as possible tools familiar to the users and avoid changing too much the way they work. These ergonomic issues call for a prudent integration of nonpreemptive techniques, which for example raise as few false alerts as possible. The domain of advanced authoring aids remain a research issue, which can involve researchers from psycholinguistics, Human-Computer Interaction, and Natural Language Processing. Overall, there exists an interest in both evaluating implemented techniques in an interactive setting (e.g. adapting discourse segmentation techniques for interactive structuring), and in adapting existing techniques for authoring aids.
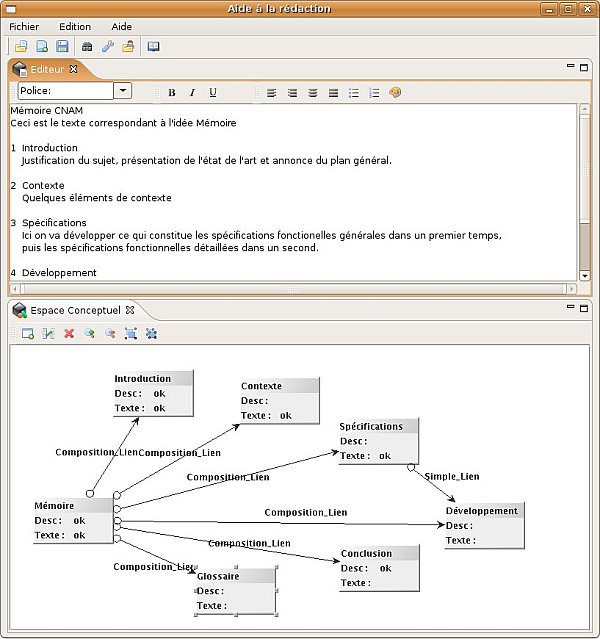
We have started to specify and implement an authoring workbench that would allow these kinds of experiments. An initial prototype (illustrated on Figure 1 below) has been implemented by a computer science student from CNAM (Debbagi, 2007). The tool consists of a kernel for the common features, and allows the addition of external plug-in modules. The overall approach, which we designed to be as "author-friendly" as possible, works in a nonpreemptive way. An author can independently describe idea networks in conceptual spaces and documents in text spaces, and link them whenever she wants. For example, an existing idea can be exported to a given document under creation: if text spans have already been associated to this idea (from within the conceptual space, and from another documents) then it can directly be reused. Conversely, the user can decide to export a particular text span to a conceptual space.
The next steps of this work will include extending the kernel part of the workbench, and adapting NLP algorithms (e.g. for discourse segmentation (Hernandez, 2004 ; Ferret, 2007)) to integrate them as plug-in modules.
References
- Alamargot, D., P. Terrier and J.M. Cellier (2005) Production, compréhension et usages des écrits techniques au travail, Octarès Editions
- Blanchon, H. and Boitet, C. (2006) Annotating Documents by Their Intended Meaning to Make Them Self Explaining: An Essential Progress for the Semantic Web, Proceeding of FQAS 2006, Milan, Italy
- Dale, R. and S. Douglas (1996) Two investigations into Intelligent Text Processing, in The New Writing Environment: Writers at Work in a World of Technology, M. Sharples and T. van der Geest eds., Springer
- Debbagi, S. (2007) Création de documents par structuration assistée d’idées, Mémoire de fin d'études d'Ingénieur CNAM
- Esposito, N. (2005) Articulation entre le contenu et le document pour la création de documents numériques, Actes de HCI International, Las Vegas, Etats-Unis
- Ferret, O. (2007) Approches endogène et exogène pour améliorer la segmentation thématique de documents, in Traitement Automatique des Langues, numéro spécial Discours et Document
- Hartley, A. and C. Paris (1997) Multilingual Document Production, Machine Translation, 12
- Hernandez, N. (2004) Description et Détection Automatique de Structure de Texte, Thèse de doctorat, Université Paris-Sud 11
- Hernandez, N., A. Max and M. Zock (2006) Aide à la rédaction: apports du Traitement Automatique des Langues, Actes de la journée d'étude de l'ATALA du 3 juin 2006 [1]
- Max, A. (2007) Contraindre le fond et la forme en domaine contraint: la normalisation de documents, in Traitement Automatique des Langues, numéro spécial Discours et Document
- Max, A. (2006) Writing for Language-impaired Readers, Lecture Notes in Computer Sciences, CICLING'06, Springer, Mexico City, Mexique
- Piolat, A., N. Isnard and V. Della (1993) Traitements de textes et stratégies rédactionnelles, in Le travail humain, tome 56, n°1
- Antidote RX, Druide Informatique [2]
- Cordial, Synapse [3]
- Prolexis, Diagonal [4]