Conceptual normalization of texts for semantic network visualization
Benoît Habert, Martine Hurault-Plantet, Cyril Grouin
Contents |
Object
Text classification and the visualization of the resulting categories facilitates the analysis of a very large number of texts. We assume that classification is more efficient when a conceptual normalization of the text is previously made, e.g. if we group together into a single token various tokens which refer to the same notion. In this way, text normalization includes lemmatization and synonymy as well as morphological derivation between different grammatical categories (for instance, the tokens displeasure and displease are different but they refer to the same notion). We produced a processing chain that performs different kinds of conceptual normalization previous to topic clustering.
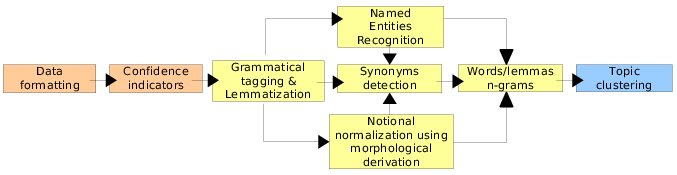
Description
The normalization processing chain includes the following modules:
- Confidence indicators and grammatical tagging
In order to optimize the efficiency of linguistic processing, i.e. to keep failure rates at a low level, it is important to process texts that are in accordance with the language rules (typographic, orthographical and grammatical). We produced a corpus certification corpus that allows us, on the one hand, to give an indicator of the cleanliness of a text, and on the other hand, to automatically correct as many mistakes as possible [4]. The tagging and lemmatization stage associates to each word, a canonical form (lemma) and a grammatical tag. This allows us to filter grammatical categories whose words make the most sense (for instance noun, verb and adjective). This stage is realized using the TreeTagger [5].
- Named Entities Recognition
This module identifies classical named entities such as place, person, and organisation names, as well as specific entities dedicated to a given application (industrial products for instance). As a result, document words, corresponding to specific entity types that are of interest to a given company, are tagged in accordance to their entity type [2].
- Notional normalization
This module aims to assemble in a same concept words that express this concept through different grammatical forms (eg. difference, different, differentiate). This treatment reduces the precision of information but aims to improve synthetic representation.
- Information adding through synonymy
This module builds lexical networks based upon pairs of words that are frequently found together within the same semantic context.
- Words/lemmas n-grams construction
Words/lemmas n-grams are continuous sequences of n words or lemmas that allow us to extract from the text, phrases that will be able to solve some ambiguity (for instance, the phrase no_problem allows us to solve the ambiguity of the word problem in a negative sentence). N-grams are built using the CMU Cambridge Statistical Language Modeling Toolkit [1].
- Topic clustering
Topic clustering groups documents according to their topic. This representation through topics produces a synthetic representation of the corpus but it loses precision and exhaustivity compared with a representation through lemmas or n-grams of lemmas. Topics are produced by the COPE software which uses a variant of the clustering k-means algorithm [3]. This software has been developed within the LIR group.
Results and prospects
This processing chain allows us to treat a very large amount of textual data and produces a classification of documents. This classification is conceived as a help for data analysis that can lead, for example, to decision making in marketing. We use this processing chain as a set of tools for preprocessing that aims to make easier data visualization from a corpus. This chain is used within two different projects: the RNTL Seven project and the RNRT Autograph project.
References
[1] Clarkson P.R. et Rosenfeld R. (1997). Statistical Language Modeling Using the CMU-Cambridge Toolkit. ESCA Eurospeech.
[2] Elkateb-Gara F. (2003). Extraction d'entités nommées pour la recherche d'informations précises. Congrès ISKO-France.
[3] Jardino M. (2004). "Recherches de structures latentes dans des partitions de "textes" de 2 à K classes". In JADT 2004.
[4] Ringlstetter, Ch., Schulz, K. U., and Mihov, S. (2006). "Orthographic Errors in Web Pages: Toward Cleaner Web Corpora" in Computational Linguistics, Vol. 32:3, p. 295-340.
[5] Schmid H. (1994). "Probabilistic Part-of-Speech Tagging Using Decision Trees". In International Conference on New Methods in Language Processing.