Attentional mechanisms with spiking neurons
Sylvain Chevallier, Philippe Tarroux, in collaboration with Hélène Paugam-Moisy (LIRIS Lyon)
Contents |
Abstract
Although vision provides huge amounts of information about the external world, robotics vision systems are often designed to fulfill specific tasks of guidance and recognition in calibrated environments and, in spite of years of attempts, has not reached a state where the power of visual mechanisms can be fully exploited. One of the main reasons for that is the complexity of visual mechanisms and brain information processing and the recent evolution of our understanding of these processes.
Image analysis require a huge computational power in order to obtain reasonable results. We propose a bio-inspired way to process input images, based on saliency detection and spiking neural computation.
General Framework
Modeling Visual Attention
Psychologists make a useful distinction between attention and pre-attention processing : the former is a top-down process, e.g. involving task-dependent or context-dependent influences. The latter is a bottom-up (BU) process, i.e. data-driven, on which we will focus here. Many models of selective visual attention with BU process have been proposed and we can distinguish three main approaches :
- Psychological models
- Image processing
- Bio-inspired computation
Computational models of visual attention set up by psychologists focus on reproducing explaining experimental data. Many psychological models try to explain or predict the behavior of neuropsychological disorders [4]. Whereas theses goals are too divergent from computational ones, some finding are interesting, e.g. the visual features. This can be understood as the different modalities of vision : color, movement, orientation, among others. Features are extracted in a parallel way during the pre-attentive stage then combined on a saliency map. Saliency map is a common idea shared in many models, psychological and computational as well. This map shows the regions resulting from the combination of all features, the saliencies.
Saliency points can also be seen as "meaningful" descriptors of an image. This formulation lead the image processing community to propose other way to extract saliency points, without combining visual features. Image processing models use information theory (local complexity or unpredictability, [7]]) or pixel distribution (local histograms, [9]). Such descriptors are used to recognize known objects or object class and give their best performance in controlled environment. They are not suited for robotics in unconstrained environment.
The bio-inspiration way aims at bringing together natural solutions and computational efficiency. It is different from producing realistic biological models as the models are simplified to get only the key properties. There is many bio-inspired models which relies on the notion of saliency map [6]. The existence of a saliency map neural correlate (in brain visual or higher areas) is broadly discussed [3].
Saliency
The very existence of a saliency map in the cortex remains unclear as long as the notion of saliency change from one author to the others. We propose this definition: a saliency is a region in a visual scene which is
- locally contrasted in terms of visual features
- globally rare in the visual scene.
An important point about saliency is the reasons leading to using it. Often, it is said that the complexity of the visual world is too high for the brain capacity or that the brain lacks the power to process a complete visual scene. This statement can be questioned because even if the individual neurons are slow and limited (in computational terms), the computational power of a massively parallel amount of them remains unmatched. The visual system is sequential and process a saliency at a time, so it is often described as a bottleneck effect. But is the brain so limited or is there a misunderstood scheme ?
We argue that the visual system find a benefit in the use of this sequential saliency extraction process. The evolution may have kept this solution for a reason, we postulate that such a sequential processing of the input may allow the emergence of some heuristic, unavailable otherwise. The exploration of a visual scene in term of sequential saccades on different key elements (the saliencies) may carry additional informations difficult or impossible to reach when the whole scene is processed in one step.
Bio-inspired approaches offer a good framework for designing efficient and robust methods to extract saliencies. We investigate the contribution of a neural-based system, as the image processing approaches have been widely explored and have shown their limitations.
Spiking Neurons
We use a neural based system to extract saliency. This class of neuron is described as the "third generation" and exhibits an impressive computational power. A spiking neuron unit models the variation of the membrane potential and fires a spike if the membrane cross the threshold. The main difference between a spiking unit and a classical sigmoid unit reside in the way of handling the time. Spiking neuron membrane potential is driven by a differential equation and takes into account the precise time of the spikes. The inputs (incoming spikes or Post Synaptic Potentials) and the output (spike send towards other units) are tagged with a precise time. This property open a new and potentially rich way for information coding, well investigated by neurobiologists [5].
Depending of the chosen parameter values, a single spiking neuron can can either integrate the information over a certain time or act as a synchrony detector, i.e. emitting spike when inputs are condensed in a small period of time. The latter behavior let emerge interesting properties when neurons are gathered in a network, such as oscillation of the overall activity or synchronization between distant unit. The neurobiological literature is full of examples of such properties.
Spiking neural networks are a complex and powerful tool, under heavy investigations. Time-based computations offer new perspectives and it seems clear now that their core property is the dynamic of the a network, i.e. how the activity is propagated among the units. A specific neuron in a spiking neural network can contribute to an assembly at a certain time and be part of another assembly later. Those kind of assembly are called dynamic assembly and can be seen as a time-shifting subnetworks or as if a single network was the sum of many overlapping layers across the time.
Spiking neuron network activity is an important concern and it can be exploited for fast computation. Biological recording of neural activity can show a very low or sparse activity when performing tasks and with very few spikes, a neural system can achieve a lot of tasks. Monkeys and humans are able to detect the presence of animals in a visual scene in an extremely short time, leaving neurons just the time to fire a single spike [10]. The information is condensed in the precise time of each spike and the relative latency between the spikes. It is possible to build a network which can take advantage of this sparse coding scheme [8]. Computations can be very fast due to the low activity of the network and it is possible to implement real-time algorithm.
Saliency Extraction
A Spiking Neural Network Architecture
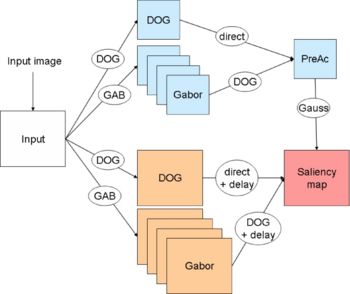
Spiking Neuron Model
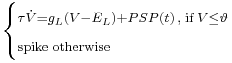
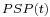 represents the influence of incoming spikes on the membrane potential (called post-synaptic potentials or PSPs) and
represents the influence of incoming spikes on the membrane potential (called post-synaptic potentials or PSPs) and 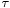 ,
, 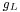 ,
, 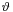 and
and 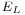 are parameters of the leaky integrate-and-fire neural model. The evolution of a PSP is commonly described by an
are parameters of the leaky integrate-and-fire neural model. The evolution of a PSP is commonly described by an 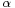 -function, like
-function, like 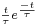 . However, there is no fast method for computing the influence of a sum of -functions. So we use a Gaussian difference model for describing the time course of a PSP, it is described in a research note available on demand.
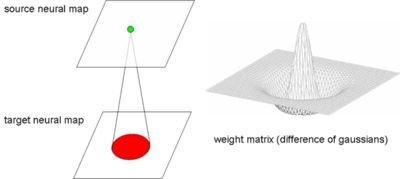
. However, there is no fast method for computing the influence of a sum of -functions. So we use a Gaussian difference model for describing the time course of a PSP, it is described in a research note available on demand.NxN neurons on the target neural maps, as shown on Fig. 2. As all neurons of a single map have the same connection pattern, a generic projective connection, called mask is defined. Masks are NxN weight matrices with delays, weights and delays are static, so they can be defined at the beginning of the simulation. The weight matrices are similar to matrix filters used in image processing. The filters used here are contrast detectors (differences of Gaussians or DOG on Fig. 1) and orientation detectors (Gabor wavelets or GAB on Fig. 1).
In an image processing approach, the resulting image is obtained by the convolution of a matrix filter and an image, and each pixel is processed in an order determined by the algorithm. With connection mask, the pixels are processed in an order determined by the input, from the more luminous to the darkest ones. This speed up the processing as only pixels which are luminous enough are processed: the darkest pixels do not trigger spikes.Results

We use this architecture on images acquired during a robot ride in our laboratory. The images are reduced from 320x240 pixels to 76x56 pixels (an example is shown on Fig. 3c) and we consider both luminance and color informations. Figure 3 shows a prototypical example of our results, saliencies are sorted according to the temporal properties of spiking neurons. The sooner a neuron emits a spike, the brighter the corresponding pixel will be (on Fig. 3a and 3b) . This neural information coding is similar to a rank order coding, but it is not limited only to the first spike.
Other bio-inspired models need a specific and time-consuming step to sort the saliencies. Our approach does not need such algorithms, as the saliency are already ordered. Besides, it is an anytime algorithm. The process can be stopped anytime and always gives a response, the results are better as the time goes by.
Conclusion
We have presented here an architecture which allows the extraction of salient locations, using a spiking neural network. This architecture benefits of the spiking neuron time-based processing to sort the saliencies. It is also worth noting that the algorithm has the anytime property. The progressive saliency extraction allows the system to give an answer each time it is required but the longer the waiting, the better the response.
References
[1] S. Chevallier, P. Tarroux and H. Paugam-Moisy. Saliency extraction with a distributed spiking neural network. ESANN 2006. 14th European Symposium on Artificial Neural Networks, Bruges, Belgium : 2006. - 209-214
[2] S. Chevallier, P. Tarroux. Extraction de saillances par un réseau de neurones impulsionnels. NeuroComp' 2006. 1ère Conférence Francophone de Neurosciences Computationnelles, Pont à Mousson, France : 2006. - 154-157
[3] J. Fecteau and D. Munoz. Salience, relevance, and firing a priority map for target selection. Trends in Cognitive Sciences 10: 382-390, 2006.
[4] D. Heinke, G. Humphreys. Computational Models of Visual Selective Attention: A Review. In G. Houghton (Ed.), Connectionist Models in Psychology, Psychology Press, 1998.
[5] C. Huetz, P. Tarroux with J.-M. Edeline, Spike timing and information transmission in biological neural networks.
[6] L. Itti, G. Rees, and J. Tsotsos, editors. Neurobiology of Attention, chapter Models of Bottom-Up Attention and Saliency. Elsevier, 2005.
[7] T. Kadir and M. Brady. Saliency, Scale and Image Description. International Journal of Computer Vision. 45 (2):83-105, November 2001.
[8] L. Perrinet. Emergence of filters from natural scenes in a sparse spike coding scheme. Neurocomputing, 2003.
[9] C. Schmid, R. Mohr and C. Bauckhage. Evaluation of Interest Point Detectors. In International Journal of Computer Vision, 37(2), 151-172, 2000.
[10] S. Thorpe, D. Fize and C. Marlot. Speed of processing in the human visual system. Nature, 381, 520-523, 1996.