ASR for less-represented languages, issues in lexical modeling
Contents |
Object
With the growing interest for technologies allowing multilinguality, more and more languages are concerned by speech technologies and by speech recognition in particular. State-of-the-Art speech recognizers require huge amounts of training data, both transcribed speech and texts. Most of the world's languages suffer from lack of training material and often have a poor representation over the web, which is being used more and more as the primary source for collecting data (principally texts) for building ASR systems. Our research is focused on lexical modeling and in particular on automatic identification of sub-word lexical units used in recognition lexicons. Subword units may help adress two main issues in ASR for less-represented languages, that are high Out-Of-Vocabulary rates and poor language model estimation.
Description
In the case of less-represented languages, it is often easier to obtain a few hours of audio data for acoustic model training, whereas it can be quite difficult to find sufficient representative texts in electronic form. To adress the high OOV rate problem observed for such languages, a data-driven word decompounding algorithm has been developped. Automatic word decompounding is investigated as a means to help select recognition units in an almost language-independent manner. Entire words and sub-word units are automatically selected in an iterative manner with a maximum likelihood criterion. We enhanced the "Morfessor" algorithm from the Helsinki University of Technology by adding properties useful for ASR (phone-based features, phonetic confusion constraint between others).
Results
As a case study, the Amharic language has been chosen. Compared to other languages for which models and systems have been developed, the Amharic audio corpus is quite small. It comprised of 37 hours of broadcast news data. In addition to the 250k word transcriptions of the audio data, about 4.6 million words of newspaper and web texts have been used for language model training. Over 340k distinct words are found in these texts. The speech recognizers all have two decoding passes, with unsupervised acoustic model adaptation after the first decoding pass. The language models are Kneser-Ney smoothed four-gram models. Results presented were all achieved on a 2h audio subset development/test corpus.
Impact of audio training data quantity
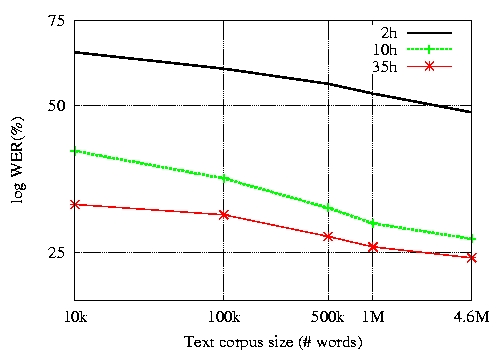
Figure 1 gives the log word error rates for the systems built with 2h, 10h, and 35h sets of acoustic training data as a function of the text corpus size used to estimate the LMs that are interpolated with the transcript LMs. Systems with acoustic models trained on 10h and 35h have somewhat similar performances when a minimum of 1M words are used to train the language models, suggesting that it at this operating point collecting text data may improve performance more than additional audio data. The best system achieved a 24.0% WER.
Automatic lexical unit selection
The basic idea in this research consists of building a decompounding model for a reference lexicon, and then using this model to decompose all words in the corpus by a Viterbi-like algorithm. An initial 133k word-based lexicon was selected, comprised of the 50k distinct words in the training data transcriptions and all words occurring at least three times in the newspaper and web texts. The out-of-vocabulary rate of the development corpus with this word list is 7\%, which is quite high compared to the OOV rates obtained for well-represented languages which are typically around 1-2\%. The relative reduction in OOV rate ranges from 30\% to 40\% depending on the properties used in the algorithm. The best performance has been obtained with all the new properties useful for ASR. This system achieved a 0.4\% absolute improvement compared to the baseline.
Recognition experiments have also been carried on Turkish, with a read speech corpus. WER reductions have also been observed. Experiments on Turkish Broadcast news data are underway.
References
J-L.Gauvain, L.Lamel and G.Adda. "The LIMSI Broadcast News Transcription System", Speech Communication, volume 37(1-2), pages 89-108, May 2002.
M.Kurimo et al. "Unlimited vocabulary speech recognition for agglutinative languages", Human Language Technology, HLT-NAACL 2006. New York, USA, 2006.
T.Pellegrini, L.Lamel. "Investigating Automatic Decomposition for ASR in Less Represented Languages", Interspeech, Pittsburgh, USA, september 2006.
T.Pellegrini, L.Lamel. "Using phonetic features in unsupervised word decompounding for ASR with application to a less-represented language", Interspeech, Antwerp, Belgium, august 2007.