Quantitative study of voicing assimilation in French: acoustic measurements vs. Bayesian decision
Contents |
Object
Voicing assimilation in French is often considered to be an all-or-none phenomenon and generally viewed as purely regressive [1,2]. More recent studies [3,4] propose that voicing assimilation is better viewed as a gradient than a categorical phonetic variation. In the reported study we address voicing assimilation in French by making use of a large corpus of radio broadcast news speech (90 hours). This kind of data differs from spontaneous speech but is closer to natural speech than the read speech materials used in most studies, with the exception of a few studies on spontaneous speech reduction (e.g. [5]). Voicing assimilation is addressed via two complementary approaches: acoustic measurements and an innovative Bayesian framework. Using the latter approach, voicing alternation is investigated globally, including a million of consonantal segments, before focusing more specifically on assimilation contexts (5% of consonants), defined as C1#C2 contacts, with C1 and C2 having opposite voice features (NV#V, V#NV). Assimilation results are compared to control situations, i.e. C1#C2 contacts where C1 and C2 have identical voice features (NV#NV, V#V). Assimilation contacts in French frequently involve function words such as in avec des, chef de guerre, cette guerre, trouve que, peuvent pas, even though more classically investigated sequences generally correspond to adjective noun contacts (république démocratique, sept jour). A large number of proper names also contribute to both assimilation contacts (Dominique Voynet, Elisabeth Guigou) and control contacts (Jacques Chirac, George Bush).
Description
In French, the main cue for voicing contrast consists in the presence/absence of glottal pulsing. The used measure is a voicing ratio (Snoeren et al.), defined as the proportion of voiced frames per phone segment. The phone segments are automatically located using the LIMSI alignment system [6], together with a canonical pronunciation dictionary. The alignments allow to locate both assimilation and control contacts. Acoustic measurements are then carried out according to voicing contact (NV#NV, NV#V, V#NV, V#V) and contact segment durations.
Concerning the Bayesian framework, a second set of alignments is carried out with a pronunciation dictionary including voicing alternation (VA) specific variants. Voicing alternation is defined as a change of the underlying voice feature f to its opposite value -f in its surface form. The voicing decision then relies on the conditional probability densities of the acoustic phone models, described by 3-state Gaussian mixture HMM models (256 Gaussians/state). Voicing assimilation can be seen as a particular case of voicing alternation, with constraints on contexts where voicing alternation is allowed. Voicing assimilation consists for a given consonant in inheriting the voicing feature (voiced, voiceless) of an adjacent consonant. In French voicing assimilation, known to be regressive, i.e. the voicing feature is inherited from the following consonant (e.g. sub-saharien: the /b/ of the prefix sub- is most probably realised as [p] due to the adjacent voiceless fricative /s/ of the word start saharien), should then favour voicing alternation of C1 rather than C2 in assimilation contexts.
Acoustic measurements
We used the F0 extraction module in Praat [7], with a 3 ms time-step and otherwise standard settings, to determine voicedness, thus, for both consonants, a voicing ratio (v-ratio) in the 0-1 range, as a measure of voicing degree. The v-ratio tells us whether a consonant is fully voiced, fully voiceless, or incompletely voiced. In the latter case, the question arises as to which portion of the consonant is voiced: does regressive assimilation entail that the observed partial voicing spreads backward from the right to the left? The role of segment duration is also investigated: are shorter segments more frequently assimilated? or more strongly assimilated?
Bayesian framework
A voice feature (VF) variable has been introduced whose value is determined using statistical acoustic phoneme models, corresponding to 3-state Gaussian mixture Hidden Markov Models: for all relevant consonants, i.e. oral plosives and fricatives their surface form voice feature is determined by maximising the acoustic likelihood of the competing phoneme models (see Fig.1).
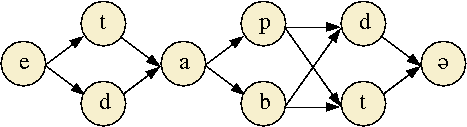
A voicing alternation (VA) measure reports
the number of changes between underlying and surface form voice
features. We first examine the validity of the proposed method: to
what extend the observed results can be considered as reliable? To do
so, we compare a global voice alternation rate, expected to remain
close to zero, and between-word voice alternation on assimilatory
C1#C2 contacts. Here alternation rates are expected to grow for C1,
given the regressive nature of voice assimilation in French.
Results
Acoustic measurements
In Figure 2 we examine how v-ratios of C1 and C2 vary according to sequence duration and contact condition. Assimilation (V#NV, NV#V) and control contact sequences (NV#NV, V#V) are grouped into four duration classes. The left part of Figure 1 shows average v-ratios for C1, the right part corresponds to C2 v-ratios. The shorter duration classes (C1#C2 below 180ms) gather a large majority (85%) of the data. Longer durations are less reliable as pauses or other events might occur between the C1#C2 contacts. We comment the two shorter duration classes. As a first observation, we can say that C1 voiceless consonants (left, upper box) have relatively high average v-ratios: 0.4 in the NV#NV control condition. As expected v-ratios increase (around 0.7) for the NV#V assimilation condition highlighting the impact of regressive assimilation. The C2 voiceless consonants (right, upper box) have very low v-ratios (below 0.2) and a potential effect of progressive assimilation remains marginal.
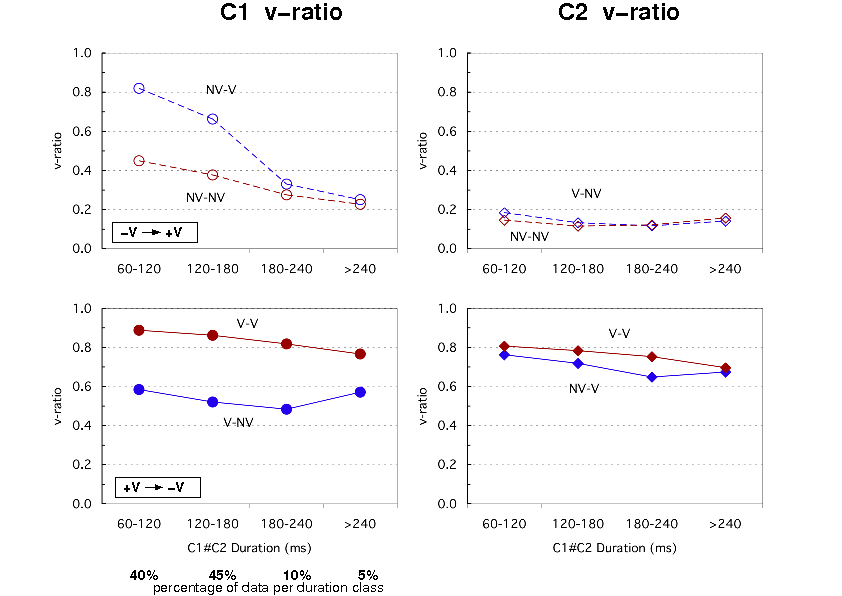
The C1 voiced consonants (left, lower box) achieve an average v-ratio close to 0.9 for the control condition. This ratio drops significantly (below 0.6) in the V#NV assimilation condition. Concerning C2 voiced consonants (right, lower box) average v-ratios remain globally between 0.7 and 0.8, however a progressive assimilation effect might explain the difference observed between V#V control and NV#V assimilation conditions.
In order to get a more informative representation than average v-ratios (Figure 2), C1#C2 v-ratio distributions are displayed in Figures 3 and 4 for the assimilation conditions V#NV and NV#V. The right part corresponds to the matrix of v-ratio measurements of C1 (vertical) and C2 (horizontal) grouped into 10 v-ratio classes. The left part shows the predictions, corresponding to the underlying voice features of C1 and C2 in both V#NV (upper) and NV#V (lower) conditions, the arrows indicate how the underlying voice features are supposed to distribute in case of regressive or progessive assimilation.
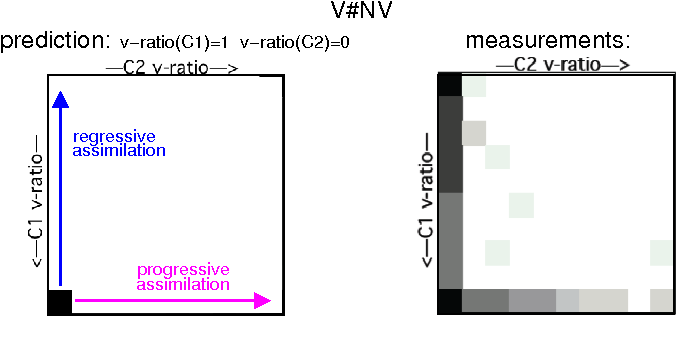
Comparing the underlying voice features to the measurements, Figure 3 confirms that assimilation is mainly regressive for V#NV contacts,
the C1 average v-ratio of 0.6 corresponds to a bimodal distribution with modal values for either fully voiced (no assimilation)
or fully voiceless (assimilation) v-ratios. Concerning C2 Figure 3 also shows a small amount of data subject to progressive assimilation.
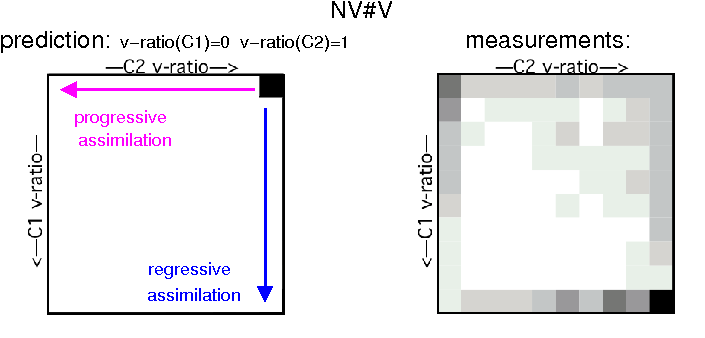
Concerning the NV#V contacts (Figure 4) the underlying voice features appear to be less stable than for the V#NV contacts: a very large amount of contacts are assimilated here and assimilation proceeds in both directions, even though assimilation remains mainly regressive.
Bayesian framework
A first question concerns the rate of alternate alignments independently of assimilation contexts. This question is related to the instrument's accuracy: in non-assimilation contexts, the use of alternates should remain low. In particular word-internally where the rate of assimilation contexts is almost negligible, alternation should remain very low. Alternations on word endings are expected to be higher than on word starts, due to regressive assimilation.
Overall voicing alternation rates
The voicing alternation (VA) measure counts the number of changes between underlying and surface form voice features on alternating consonants. A VA rate is then defined on alternating consonants (independently of their context) as the number of times an alternating consonant with voice feature f is classified as voice feature -f. The overall VA rate includes alternations in assimilation contexts, however their proportion among alternating consonants remains low: less than 2%.
A global VA rate of 2.7 is measured on a total of 1M alternating consonants. This low alternation rate gives an idea of the instrument's accuracy, as well as of the methodological validity. Alternations can be explained either by decision errors, by noise ("errors") in the observed speech signal: unexpected variants, overlapping music... and more importantly by assimilations. Alternation rates are also examined according to the position of the consonant in the word skeleton: word-internal vs boundary and, for the latter, word-start vs word-end [9].
Voicing alternation in assimilation contexts
The data are partitioned into 5 subsets depending on the word boundary type: two assimilating (NV#V, V#NV), two corresponding control (V#V, NV#NV) conditions and a global control condition (NON) including all the remaining items, not considered in the first 4 subsets. Table 1 shows VA rates for C1 (word-final) and for C2 (word-initial).
| C1 | C1#C2 | C2 | |
|---|---|---|---|
| VA rate | condition | VA rate | |
| control | 9 | NV#NV | 1 |
| assimilation | 24 | NV#V | 4.5 |
| assimilation | 20 | V#NV | 1 |
| control | 4 | V#V | 3 |
| control | 5 | NON | 2 |
Table 1: VA rates for C1 and C2 consonants (final and initial word boundary positions) using 5 complementary conditions. The NON condition includes all relevant word boundary consonants for which C1 and C2 are not both in the set of alternating consonants.
Concerning C1, Table 1 shows a
strong tendency to regressive assimilation for both NV#V (24%) and
V#NV (20%). A slight asymmetry can be observed in favour of NV#V: a
voiceless consonant becomes more often voiced due to regressive
assimilation than the reciprocal configuration. Figures also exhibit a
weak tendency of C1-voicing, independently of regressive
assimilation: comparing NV#NV alternation rates (9%) to the
corresponding V#V rate (4%) shows that a voiceless consonant
easier gets voiced than the opposite. Concerning C2, VA rates are very low, underlining the stability
of word-start consonants. However a cross-condition comparison
reveals two weak tendencies: first progressive assimilation for the NV#V condition
(4.5%) and second C2-devoicing (3% on V#V, 4.5% on
NV#V). In word-initial C2 position, a voiced consonant easier
changes to its voiceless counterpart than the reverse.
Summary and conclusions
In this study, we report a voicing assimilation study in French, based on a large corpus of journalistic speech (90h). Two complementary methods, acoustic measurements and Bayesian decision, contribute to examine some essential aspects of voicing assimilation, and allow to draw similar conclusions: voicing assimilation is not purely unidirectional: at least at the acoustic level, some interaction seems to take place between C1 and C2 degrees of voicing.
Using voicing ratio as a measure of voicing degree, incomplete voicing of C1 was found in all situations of C1#C2 consonant contact. Voicing itself is fairly gradient, but this does not entail that voicing assimilation also be gradient. Rather, voicing assimilation might be categorical in French, contrary to claims made in [3]. A more in-depth discussion can be found in [8], where differences in degree of assimilation are also investigated across stop and fricative classes.
The presented Bayesian framework allows for a unified analysis of voice alternation and assimilation on a large scale. An overall voice alternation rate of 2.7% has been measured, thus calibrating the method's accuracy. The VA rate remains below 2% word-internally and on word starts and raises up to 9% on lexical word endings. In assimilation contexts rates grow significantly (>20%), highlighting regressive voicing assimilation. Results also suggest weak tendencies for progressive (devoicing) assimilation, as well as C1 voicing and C2 devoicing independently from assimilation contexts.
Beyond the results presented here, our study shows that the identity of assimilating phoneme sequences, as well as lexical cooccurrence frequency, POS, duration and stress are interfering factors. For the assimilation issue proper, additional insight can be gained by a more extensive study of the link between voicing alternation and these factors.
References
[1] Rigault, A. 1967. L'assimilation consonantique de sonorité en français: étude acoustique et perceptuelle. Voice assimilation of consonants in French: An acoustic and perceptual study. Proc. 6th ICPhS, Prague, 763-766.
[2] Tranel, B. 1987. The sounds of French. Cambridge: Cambridge University Press.
[3] Snoeren, N., Hallé, P., & Segui, J. 2006. A voice for the voiceless: Production and perception of assimilated stops in French. Journal of Phonetics, 34, 241-268.
[4] Gow, D. W., Im, A. M. 2004. A cross-linguistic examination of assimilation context effects. Journal of Memory and Language 51, 279-296.
[5] Duez, D. 1995. On spontaneous French speech: aspects of the reduction and contextual assimilation of voiced stops. Journal of Phonetics 23, 407-427.
[6] J.L. Gauvain, L.F. Lamel, G. Adda, "The LIMSI Broadcast News Transcription System", Speech Communication, vol.37(1-2), pp. 89-108, 2002.
[7] Boersma, P., Weenink, D. 1992-2004. Praat: A system for doing phonetics by computer [Computer program]. http://www.praat.org.
[8] Hallé, P., Adda-Decker, M., 2007. Voicing assimilation in journalistic speech. Proc. 16th ICPhS, Saarbrücken.
[9] Adda-Decker, M., Hallé, P. 2007. Bayesian framework for voicing alternation and assimilation studies on large corpora in French, Proc. 16th ICPhS, Saarbrücken.