Speech Translation
Daniel Déchelotte Gilles Adda Eric Bilinski Olivier Galibert Jean-Luc Gauvain Lori Lamel Holger Schwenk
Contents |
Object
This work addresses two problems that specifically arise when a system combines automatic speech recognition (ASR) and machine translation (MT). The first difficulty is the various discrepancies between the training material used by the MT system and the data being actually translated during testing. The second open question relates to the tuning of the ASR system in order to globally maximize the system's end-to-end performance from the audio to the text in the target language. Both problems are discussed below.
Translating ASR output is arguably quite a different problem than translating formal texts. In the first part of this work, we describe how our system addresses the following three items:
- The transcription may contain disfluencies, which naturally occur in speech. MT systems should recognize and ignore hesitations, repetitions and false starts.
- Speech is not explicitly segmented into sentences, and recovering that segmentation automatically is a challenging task that involves both acoustical and linguistic information. Moreover, clear conventions are lacking with respect to the placement of finer punctuation marks (e.g., commas, columns) and ASR system are therefore often built and tuned without punctuation marks.
- Finally, ASR's text normalization might differ from the one expected by the MT system, which could lead to suboptimal translation. Translating the output from external ASR systems, or the ROVER combination of various systems, is particularly subject to this pitfall.
The second part of this work aims at confirming or infirming the intuition that a STT system that breaks phrases might lead to poorer translations when translated by a phrase-based MT system than a STT system of comparable word error rate (WER) that preserves more phrases, as suggested by [Gales and al., 2007].
Description
Data
The task considered in this work is the translation of the European Parliament Plenary Sessions (EPPS) from English to Spanish, in the framework of the TC-Star project.
Overview of the ASR system
Word recognition is performed in four passes, where each decoding pass generates a word lattice with cross-word, position-dependent, gender-dependent acoustic models, followed by consensus decoding with 4-gram and pronunciation probabilities. Unsupervised acoustic model adaptation is performed for each segment cluster using the CMLLR and MLLR techniques prior to each decoding pass. The lattices of the last two decoding pass are rescored by the neural network (NN) language model interpolated with a 4-gram backoff language model. The total decoding time is about 6xRT [Lamel and al., 2006].
The English pronunciations are based on a 48 phone set (3 of them are used for silence, filler words, and breath noises). In the reduced phone set, used in all passes but the first one, pronunciations are represented with 38 phones, formed by splitting complex phones. A pronunciation graph is associated with each word so as to allow for alternate pronunciations, including optional phones. The 60k case-sensitive vocabulary contains 59993 words and has 74k phone transcriptions. Compound words for about 300 frequent word sequences subject to reduced pronunciations were included in the lexicon, as well as the representation of 1000 frequent acronyms as words.
The Spanish pronunciations are based on a 27 phone set (3 of them are used for silence, filler words, and breath noises). A second reduced phone set dictionary merges variants for s/z and r/R which are poorly distinguished by the common word phonetization script. Pronunciations for the case-sensitive vocabulary are generated via letter to sound conversion rules, with a limited set of automatically derived pronunciation variants. While the rules generate reasonable pronunciations for native Spanish words and proper names, other words are more problematic. The Unitex ([1]) Spanish dictionary was used to locate likely non-Spanish words, which belong to several categories: typos (which were fixed at the normalization level); Catalan words, borrowed words like sir or von, non-Spanish proper nouns which were hand-phonetized by a native speaker; and acronyms. Non-Spanish proper nouns were the most difficult to handle, especially those of Eastern European origin where the variability in the audio data shows that native Spanish speakers do not necessarily know how to pronounce them. The decision taken was to use the perceived phonetization for the names which were represented in the audio data, and use the native speaker's intuition for the rest. Although including non-Spanish phones to cover foreign words was considered, these were too infrequent to estimate reliable models so they were replaced with the closest Spanish phone. Acronyms that tend to be pronounced as words were verified by listening to the audio data or phonetized by a native speaker. The final lexicon has 94871 pronunciations for 65004 entries.
Table 1 summarizes the number of words, phones and pronunciations used by the Spanish and English speech recognition systems.
| Language | English | Spanish |
| Nb of words | 60k | 65k |
| Nb of phones | 48+3 / 38+3 | 27+3 / 25+3 |
| Nb of pronunciations | 74k / 74k | 94k / 78k |
Table 2 gives the recognition results for the evaluation systems on the TC-STAR Dev06 and Eval06 data sets. The WERs of the Feb05 systems on the Dev06 data are also given. The overall Spanish WER is 10.7%. Relative word error rate reductions of about 30% were obtained for both the English and Spanish systems on the Dev06 EPPS data.
| Language | Task | Feb05 System | March06 System | |
| Dev06 | Dev06 | Eval06 | ||
| English | EPPS | 14.0 | 9.8 | 8.2 |
| Spanish | EPPS | 9.8 | 6.9 | 7.8 |
| Cortes | 13.3 | |||
Overview of the MT system
The MT system is built upon the open-source, state-of-the-art phrase-based decoder Moses, and was trained with the scripts distributed with the software package. The translation process employs a two-pass strategy. In the first pass, Moses generates n-best lists with a standard 3-gram language model and provides eight partial scores for each hypothesis. In the second pass, the n-best lists are rescored with a 4-gram neural network language model and the final hypothesis is then extracted. Each of the two passes uses its own set of eight weights and is tuned separately.
Making ASR output resemble MT's training data
Case and punctuation

Both the words and the timing information contained in the input CTM are used to generate a flat, consensus-like lattice. More precisely, each word in the CTM file leads to the creation of one node and three edges, to account for its three alternative capitalizations (all-lowercase, capitalized or all-uppercase). Between words, edges are created as shown in Figure 1 to optionally insert a period or a comma.
The constituted lattice is then rescored by a special-purpose language model. Frequencies of periods and commas have been computed over the EPPS training corpus and the available development data to provide characteristics to aim for. It was estimated that 3.5% of all tokens were periods and 5% were commas, amounting to roughly one period every 29 tokens and one comma every 20 tokens. Two quantities may be tuned in the proposed algorithm:
- the penalty (or bonus) held by the edges with a punctuation mark (see lattice excerpt in Figure 1),
- a duration
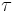 used as follows: a mandatory period is inserted at pauses longer than .
used as follows: a mandatory period is inserted at pauses longer than .
Disfluency removal, and normalizations
Hesitations and filler words are easy to spot and remove. Additionally, repeated words are removed, leaving only the first occurrence.
The normalization required for the MT system might differ from the one of the
STT system, for example for key words like Mister or Mrs..
Spelled out acronyms are consolidated into a single word, as they appear in the MT training data.
Lastly, STT's output might contain a relatively high frequency of contracted
forms, such as it's or can't.
Those contracted forms are present in the EPPS data, but at a much lower
frequency, and are therefore expanded before translation. In this work,
ambiguous forms were deterministically expanded to an arbitrary, but likely,
form.
Recomposition of compound words
A tool was designed to recover the compound words when needed. This
tool uses n-gram counts extracted from the training data used by the MT
system to, e.g., produce the compound word pro-US should this unigram
be more frequent in the training data than the bi-gram pro US.
Compounds with up to three hyphens (such as end-of-the-year) may be
recreated this way.
Results
Impact of case and punctuation
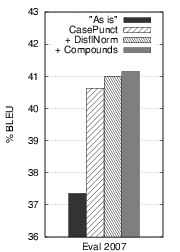
As is: translation of the CTM file provided by the evaluation committee. CasePunct: prior to translation, restoration of case and punctuation. DisflNorm: disfluency removal and renormalization. Compounds: compound recomposition.With an increase greater than 3 points BLEU, from 37.4 to 40.6, the step appears to play a crucial role in reducing the mismatch between a typical ASR output and what our MT system expects to perform at its best. After investigation, it appears that not only the punctuation helps avoid the BLEU brevity penalty, it is also useful to pick the right phrases and, eventually, to produce a correct translation.
Impact of disfluency removal and renormalization
This step provides gains of 0.4 on the test data. Most of the changes consists of acronym restorations and contracted form expansions.
Impact of compound recomposition
This step modified half less words than the previous one did, and its impact
in BLEU is even slighter, although always positive, with gains around 0.2. It noticeably allowed the MT system to correctly
translate numbers like twenty two into veintidós instead of veinte dos.
Experiments with different STT systems
| Set | ASR | MT | |||
| System | WER | BLEU | # phrase pairs | BLEU | |
| Dev06 | Rover | 7.18 | 70.22 | 2231k | 43.58 |
| Limsi CD | 9.14 | 63.98 | 2260k | 42.95 | |
| Limsi MAP | 9.53 | 63.92 | 2264k | 43.05 | |
| Eval07 | Rover | 7.08 | 67.92 | 2103k | 41.15 |
| Limsi CD | 9.33 | 61.29 | 2123k | 40.30 | |
| Limsi MAP | 9.66 | 61.14 | 2130k | 40.19 | |
Table 3 gathers the results obtained in this series of experiments. The upper-half of the table (dev06) contains a surprising inversion: although Limsi MAP has as expected a higher WER than Limsi CD, its translation is better by a short margin. In an attempt to explain this inversion, we compared the number of phrase pairs whose source counterpart is included in the input text. Limsi MAP recruits slightly more phrase pairs than Limsi CD and ROVER, which is in no way an indicator of better translations but tends to confirm our intuition that performing CD on a single system breaks phrases and performing a ROVER combination even more so. We then computed the ASR-BLEU for all systems, since this score also takes into account phrases of up to four words. However, Limsi CD was found to score a higher BLEU than Limsi MAP. In addition, the inversion did not occur on the eval07 data, preventing us from drawing any definitive conclusion at that point, except that ASR-WER remains in these experiments the best indicator of the overall ASR+MT performance.
References
[1] Improved Machine Translation of Speech-to-Text outputs, Daniel Déchelotte, Holger Schwenk, Gilles Adda and Jean-Luc Gauvain. In Proc. of Interspeech 2007.
[2] The LIMSI 2006 Tc-Star EPPS transcription systems, Lori Lamel, Jean-Luc Gauvain, Gilles Adda, Claude Barras, Eric Bilinski, Olivier Galibert, Agusti Pujol, Holger Schwenk, Xuan Zhu. In Proc. of ICASSP 2007.