Question Answering on Speech transcription; the QAST evaluation
G. Adda E. Bilinski O. Galibert S. Rosset
Contents |
Object
In the QA and Information Retrieval domains progress has been observed via evaluation campaigns ([1), [2], [3]). In these evaluations, the systems handle independent questions and should provide one answer to each question, extracted from textual data, for both open domain and limited domain. Therefore, as a large part of human interactions happens through speech, e.g. meetings, seminars, lectures, telephone conversations, current factual QA systems needs a deep adaptation to be able to access the information contained in these data. A new pilot track called QAst (Question-Answering on Speech Transcripts) has been organized as part of the CLEF evaluation ([4]). we present the architecture of the two QA systems developed in LIMSI for the QAst evaluation ([5], [6]).
Description
Our QA systems are part of a bilingual (English and French) Interactive QA system called Ritel [6] and as such the speed aspect has specifically been taken into account. In order to achieve such a speed, we developped our own indexer server.
The indexation system uses an hybrid memory/disk index to allow quick retrieval of interesting passages of documents based on boolean search of (annotation type,value) pairs. Using these passages, the information extraction module finds the (probable) answer using its predicted type obtained from the analysis of the question.
The first system uses handcrafted rules for small text fragments (snippet) selection and answer extraction. The second one replaces the handcrafting with an automatically generated research descriptor. A score based on those descriptors is used to select documents and snippets. The extraction and scoring of candidate answers is based on proximity measurements within the research descriptor elements and a number of secondary factors.
![S(A) = \frac{[w(A) \sum_{E} \max_{e=E} \frac{w(E)}{(1+d(e, A))^\alpha}]^{1-\gamma} \times S_{snip}^{\gamma}}{C_d(A)^{\beta} C_s(A)^{\delta}}](../upload/math/9/4/8/948b52fbfb592afc44f93a4e155a42d2.png)
In which:
-
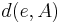 is the distance to each element
is the distance to each element  of the snippet, instantiating a search element
of the snippet, instantiating a search element 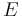 of the DDR
of the DDR
-
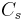 is the number of occurrences of A in the extracted snippets,
is the number of occurrences of A in the extracted snippets, 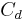 in the whole document collection
in the whole document collection
-
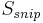 is the extracted snippet score
is the extracted snippet score
-
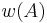 is the weight of the answer type and
is the weight of the answer type and 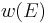 the weight of the element in the DDR
the weight of the element in the DDR
-
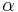 ,
, 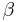 ,
, 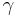 and
and 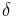 are tuning parameters estimated by systematic trials on the development data. , ,
are tuning parameters estimated by systematic trials on the development data. , , 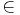
![[0,1]](../upload/math/c/c/f/ccfcd347d0bf65dc77afe01a3306a96b.png) and
and ![[-1,1]](../upload/math/d/0/6/d060b17b29e0dae91a1cac23ea62281a.png)
An intuitive explanation of the formula is that each element of the DDR adds to the score of the candidate proportionally to its weight () and inversely proportionally to its distance of the candidate(). If multiple instance of the element are found in the snippet only the best one is kept (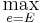 ). The score is then smoothed with the snippet score () and compensated in part with the candidate frequency in all the documents () and in the snippets ().
). The score is then smoothed with the snippet score () and compensated in part with the candidate frequency in all the documents () and in the snippets ().
Results
Both systems have been tested in the 2007 QAst evaluation. IThe QA systems are evaluated on four different tasks: QA on manually transcribed lectures (T1), QA on automatically transcribed lectures (T2), QA on manually transcribed meetings (T3) and QA on automatically transcribed meetings (T4). Table 1 shows the results of this evaluation. 5 maximum answers could have been returned by the systems. The metrics used for this evaluation are~: the percentage of correct answers given in the first position (1st Rank), the mean reciprocal rank on the 5 first answers (MRR). In order to examine the loss caused by the answer extraction and scoring, we added the percentage of correct answers regardless of their ranking (Recall). This last measure gives a good idea of what the results could be if the answer scoring was perfect.
| Task | System | Acc. (%) | MRR | Recall (%) |
|---|---|---|---|---|
| T1 | Sys1 | 32.6 | 0.37 | 43.8 |
| Sys2 | 39.7 | 0.46 | 57.1 | |
| T2 | Sys1 | 20.4 | 0.23 | 28.5 |
| Sys2 | 21.4 | 0.24 | 28.5 | |
| T3 | Sys1 | 26.0 | 0.28 | 32.2 |
| Sys2 | 26.0 | 0.31 | 41.6 | |
| T4 | Sys1 | 18.3 | 0.19 | 22.6 |
| Sys2 | 17.2 | 0.19 | 22.6 |
Conclusions & Perspectives
We presented the Question Answering systems used for our participation to the QAst evaluation. Two different systems have been used for this participation. The two main changes between System 1 and System 2 are the replacement of the large set of hand made rules by the automatic generation of a research descriptor, and the addition of an efficient scoring of the candidate answers. The results show that the System 2 outperforms the System 1. The main reasons are:
- Better genericity through the use of a kind of expert system to generate the research descriptors.
- More pertinent answer scoring using proximities which allows a smoothing of the results.
- Presence of various tuning parameters which enable the adaption of the system to the various question and document types.
These systems have been evaluated on different data corresponding to different tasks. On the manually transcribed lectures, the best result is 39% for Accuracy, on manually transcribed meetings, 24% for Accuracy. There was no specific effort done on the automatically transcribed lectures and meetings, so the performances only give an idea of what can be done without trying to handle speech recognition errors. The best result is 18.3% on meeting and 21.3% on lectures.
From the analysis of the results, performance can be improved at every step. For example, the analysis and routing component can be improved in order to better take into account some type of questions which should improve the answer typing and extraction. The scoring of the snippets and the candidate answers can also be improved. In particular some tuning parameters (like the weight of the transformations generated in the DDR) have not been optimized yet.
References
- [1] E. M. Voorhees, L. P. Buckland. The Fifteenth Text REtrieval Conference Proceedings (TREC 2006), In Voorhees and Buckland eds. 2006.
- [2] B. Magnini, D. Giampiccolo, P. Former, C. Ayache, P. Osenova, A. Penas, V. Jijkown, B. Sacaleanu, P. Rocha, R. Sutcliffe. Overview of the CLEF 2006 Multilingual Question Answering Track. Working Notes for the CLEF 2006 Workshop. 2006.
- [3] C. Ayache, B. Grau, A. Vilnat. Evaluation of question-answering systems : The French EQueR-EVALDA Evaluation Campaign. Proceedings of LREC'06, Genoa, Italy.
- [4] J. Turmo, P. Comas, C. Ayache, D. Mostefa, S. Rosset, L. Lamel. Overview of QAst 2007. Working Notes of CLEF Workshop, ECDL conference, septembre 2007.
- [5] S. Rosset, O. Galibert, G. Adda, E. Bilinski. The LIMSI participation to the QAst track. Working Notes of CLEF Workshop, ECDL conference, septembre 2007.
- [6] S. Rosset, O. Galibert, G. Adda, E. Bilinski. The LIMSI Qast systems: comparison between human and automatic rules generation for question-answering on speech transcriptions. In Proceeding of IEEE Workshop on Automatic Speech Recognition and Understanding, Kyoto, Japan. Dec. 2007.
- [7] B. W. . van Schooten, S. Rosset, O. Galibert, A. Max, R. op den Akker, G. Illouz. Handling speech input in the Ritel QA dialogue system. 2007. Proceedings of Interspeech'07. Antwerp. Belgium. August 2007.