Dialog management in a interactive and open domain QA system
O. Galibert G. Illouz A. Max S. Rosset B. van Schooten
Contents |
Object
The Ritel system aims to provide open-domain question answering to casual users by means of a telephone dialogue. Providing a sufficiently natural speech dialogue in a QA system has some unique challenges, such as very fast overall performance and large-vocabulary speech recognition. Speech QA is an error-prone process, but errors or problems that occur may be resolved with help of user feedback, as part of a natural dialogue.
Ritel Plateform
The system architecture is highly distributed and based on servers and specialized modules that can exchange messages.
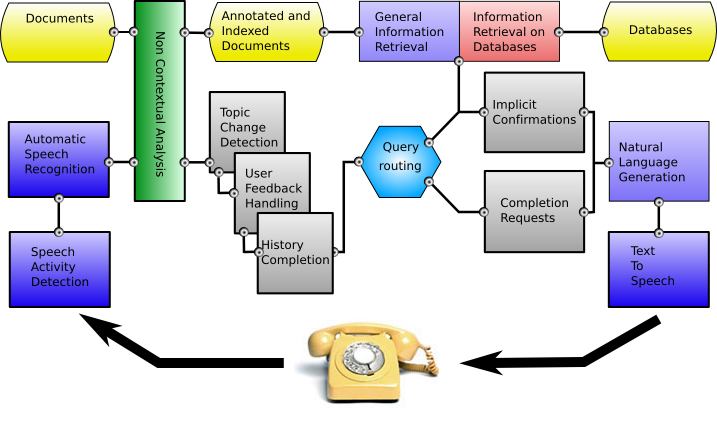
The different components of this system are:
- The Speaker Activity Detection and the Automatic Speech Recognition systems. The ASR is the one described in [1]. The acoustic models which have been built from audio data comprised of 5 hours from the Ritel corpus and 70 hours from the Arise corpus [2]. The language models have been created by interpolating various sources on the Ritel development corpus (1 hour). The vocabulary is composed of about 65K words. The out-of-vocabulary rate is 0.8% on the development corpus and 0.4% on the test corpus.
- The Non Contextual Analysis (NCA). Analysis of both indexed documents and user utterances are handled by the same module. The general objective of NCA (see [1] for details) is to find the bits of information that can be of use for search and extraction, which we call pertinent information chunks. These can be of different categories: named entities, linguistic entities (e.g. verbs, prepositions), or specific entities (e.g. scores). All words that do not fall into such chunks are also annotated by following a longest-match strategy to find chunks with coherent meanings. Specific types of entities were added to improve communication management. The types that should be detected correspond to two levels of analysis: named-entity recognition and chunk-based shallow parsing. The analysis uses an in-house word-based regular expression engine (wmatch) and handcrafted rules which have access to various lists for names, countries, cities, etc.
- The Question-answering system. The indexing server main role is to retrieve snippets, i.e. lines of documents corresponding to a given query. Queries take the form of a list of type/value pairs and lone types. If no results can be found that match the query exactly, backoff rules are applied. For a detailed description, see [1].
In a QA dialogue, we expect users to ask questions in the context of previous utterances, i.e. follow-up questions (FQ) [3]. Ritel handles these by adding elements coming from the dialogue history (context completion) by means of semantic matching. This form of completion relies heavily on the defined entities and matching rules. We rely on confirmation and user feedback to repair errors made during this process.
Description
Both speech and QA systems are known for their high error rates. Ritel is no exception. There are different sources of noise in our system, in particular ASR, information retrieval (IR), and context completion. Additionally, the ASR and context completion modules do not yield any confidence ratings, which means that it is hard to make out when or where errors occur. So, we consider feedback from the user an important mechanism for handling these sources of error. We identify several ways to do this:
- Confirm the material that we decide to feed into the IR (confirming both ASR and context completion in one go)
- Confirm the answer (confirming IR)
- Confirm topic or let the user express topic (confirming context completion and answer type)
- Let the user repeat him/herself, with or without varying formulations (confirming in particular ASR and possibly IR and context completion)
In our confirmation model, we separate the dialogue context used for confirmation of the current question from that used for FQ history completion, so that we obtain two separate contexts. Confirmation occurs in a cycle, which is completed only after the system has obtained enough material to perform IR and give an answer, and the user (implicitly or explicitly) confirms satisfaction with the system's answer. So, as long as the user gives negative feedback or tries to correct the system's confirmations, s/he is enabled to adapt the query until it is deemed satisfactory. When the cycle ends, the confirmation context is copied to the FQ context, and a new cycle is started (see also figure 1).
| U1: On what continent lies Botswana ?' | ASR: on what continent lies {fw} the | conf.context: kw = {continent, lies} qtype = location FQ context: (empty) |
| S1: You are looking for a location, but what precisely do you want to know | ||
| U2: The continent of Botswana | ASR: the continent of Botswana | conf.context: kw=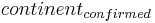 ,lies,Botswana} qtype= ,lies,Botswana} qtype=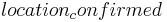 , FQ context: (empty) , FQ context: (empty)
|
| S2: You are looking for a location related to continent and Botswana. I think it's Africa. Your next question? | ||
| U3: What is its land area | ASR: what is its land area | conf.context: kw = {land area} qtype = number,
FQ context: kw = {continent, lies, Botswana} ... |
Dialogue management partakes in the QA process at two specific points: handling the user's confirmations after NCA but before FQ context completion, and generating an utterance after QA has finished. It makes use of the following natural language processing techniques: dialogue act recognition by means of the special dialogue NCA tags; topic change detection, which is performed as part of FQ history completion; and importance ranking of keywords based mostly on their types. Context is modelled by adding salience levels to each keyword, based on their ranking and frequency of mention. In particular, higher ranked keywords which have not yet been confirmed have priority in confirmation, and a keyword is considered confirmed when it is mentioned twice by the user during one confirmation cycle.
Results
For evaluating the dialogue capability of the system, 15 dialogs were collected. These comprise a total of 244 user utterances.
To measure how well the ASR managed to recognise the relevant information in the different types of utterance, we subdivided the ASR results according to whether the essential information was recognised correctly or not. We found that 131 utterances (54%) were sufficiently well recognised, that is, all relevant keywords and answer type cues were recognised, as well as any relevant communication management cue phrases. Some 76 (31%) were partially recognised, that is, at least part of the IR material and dialogue cues. This leaves 37 utterances (15%) which were not recognised to any useful degree.
We found some user act types where the ASR performance distribution deviates significantly from the overall one. Relatively well recognised were topic announcements, negative feedback, and non-self-contained FQs, as we predicted. Particularly ill-recognised were reformulations, self-contained FQs, and repetitions. This seems to be related to the presence of domain-specific keywords such as named entities, which were the toughest for the ASR. Interesting here is that non-self-contained FQ were better recognised than self-contained ones because, typically, the named entities were left out. This suggests that non self-contained FQ, while in the minority in our dialogues, can be useful if we have already established the most difficult keywords earlier in the dialogue.
To further examine the dialogue interactions between user and system, we look at the subdivision of the different system utterance types, the user's feedback utterances, and the relationships between them. There were 229 system responses in total. Most user feedback is implicit, consisting of informs (users giving partial information in a non-question form, mostly responding to a system question), and repetitions and reformulations. A minority were direct negative responses or explicit announcements of a new topic. So, we find that almost all corrections are repetitions or informs. As far as our confirmation strategy is concerned, it appears that confirmation was not picked up in the sense that users confirmed or disconfirmed anything explicitly, but it was picked up in the sense that users used it todetermine whether they were unsatisfied with the response. What users mostly did was essentially repeat when they found the system reply unsatisfactory, which means that the "repeat at least twice" kind of confirmation will work well.
If only we can detect the difference between when the user repeats or when the user poses a new question, we can use this to handle confirmation properly. However, it is not clear how to do this. Most repetitions and reformulations have no or few surface cues to help detect them, although informs could be detected by looking at the absence of a question form.
The system was quite successful at detecting topic change announcements. This was less so for explicit topic/type mentions. While the system tags phrases that can be considered cues for topics, we found no significant correlations with topic announcements, topic shifts, or self-contained versus non-self-contained questions.
Conclusion & Perspectives
We found that users seldomly reacted directly to the implicit confirmations, but tended to react by repeating and rephrasing. This appears consistent with findings on other, non-QA dialogue systems. Possibly, explicit confirmation may be useful, if we can determine in what cases to confirm explicitly. We did find that spotting repeating keywords, as well as recognising topic shifts and topic announcements, appear to be successful strategies for confirmation and handling dialogue context.
References
- [1] S. Rosset, O. Galibert, G. Illouz, A. Max. Integrating Spoken Dialog System and Question Answering: the Ritel Project". In InterpSpeech'06, Pittsburgh, USA, Sept. 2006.
- [2] L. Lamel, S. Rosset, J.L. Gauvain, S. Bennacef, M. Garnier-Rizet, B. Prouts. The LIMSI Arise System. Speech Communication 31:4. 2000.
- [3] B. W. van Schooten, R. op den Akker. Follow-up utterances in (QA) dialogues. Traitement Automatique des Langues. 46:3, 2006.