Multi-Stage Speaker Diarization for Meetings
X. Zhu C. Barras L. Lamel J.L. Gauvain
Contents |
Object
Speaker diarization, also called speaker segmentation and clustering, is the process of partitioning an input audio stream into homogeneous segments according to speaker identity. Speaker diarization was evaluated in the Rich Transcription (RT) evaluation series conducted by NIST for broadcast news data from 2002 to 2004, and in the meeting domain since 2005. The LIMSI speaker diarization system for meetings was presented to RT 2006 and 2007 evaluations. This system builds upon the baseline diarization system designed for broadcast news data and combines an agglomerative clustering based on Bayesian information criterion (BIC) with a second clustering using state-of-the-art speaker identification (SID) techniques. Since the baseline system has a high missed speech error rate on meetings, a different speech activity detection (SAD) approach based on the log-likelihood ratio (LLR) between the speech and non-speech models trained was explored. The resulting diarization system gives comparable results on both the RT-07S conference and lecture evaluation data for the multiple distant microphone (MDM) condition.
Description
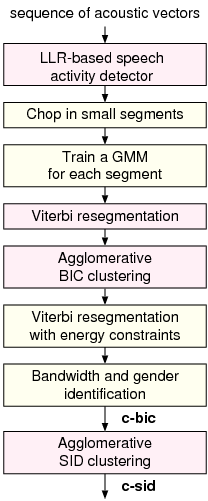
The multi-stage clustering architecture for speaker diarization proposed for broadcast news data [1] provided state-of-the art performance in NIST and ESTER evaluations. The general architecture of the system is shown Fig. 1.
Speech is extracted from the signal by using a Log-Likelihood Ratio (LLR) based speech activity detector. The LLR of each frame is calculated between the speech and non-speech models with some predefined prior probabilities. To smooth LLR values, two adjacent windows with a same duration are located at the left and right sides of each frame and the average LLR is computed over each window. Thus, a frame is considered as a possible change point when a sign change is found between the left and right average LLR values. When several contiguous change candidates occur, the transition point is assigned to the maximum of difference between the averaged ratio of both windows.
Initial segmentation of the signal is performed by a local divergence
measure between two adjacent sliding windows.
In a first agglomerative clustering stage, each segment seeds
a cluster 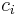 modeled by a single Gaussian with a full
covariance matrix
modeled by a single Gaussian with a full
covariance matrix 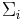 estimated on the
estimated on the 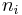 acoustic frames of
each segment output by Viterbi resegmentation. The BIC criterion
is used both for the inter-cluster distance measure and the stop criterion:
acoustic frames of
each segment output by Viterbi resegmentation. The BIC criterion
is used both for the inter-cluster distance measure and the stop criterion:
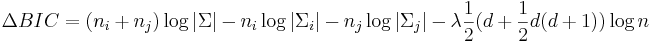
where 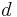 is the dimension of the feature vector space and
is the dimension of the feature vector space and 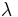 weights the BIC penalty.
weights the BIC penalty.
After the BIC clustering stage, speaker recognition methods are used to improve the quality of the speaker clustering. Feature warping normalization is performed on each segment using a sliding window of 3 seconds in order to map the cepstral feature distribution to a normal distribution and reduce the non-stationary effects of the acoustic environment. The GMM of each remaining cluster is obtained by maximum a posteriori (MAP) adaptation of the means of an Universal Background Model (UBM) composed of 128 diagonal Gaussians. The second stage of agglomerative clustering is carried out on the segments according to the cross log-likelihood ratio:
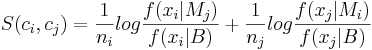
where 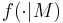 is the likelihood of the acoustic frames given the
model
is the likelihood of the acoustic frames given the
model 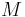 , and is the number of frames in cluster .
The clustering stops when the cross log-likelihood ratio between
all clusters is below a given threshold
, and is the number of frames in cluster .
The clustering stops when the cross log-likelihood ratio between
all clusters is below a given threshold 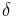 optimized on the development data.
optimized on the development data.
Results
LIMSI participated in the NIST RT-07S meeting recognition evaluation to the speaker diarization
task for both the conference and lecture meeting data on the multiple distant microphones (MDM)
and single distant microphone (SDM) audio input conditions.
For the MDM test condition, the speaker diarization system is performed on the beamformed
signals created by the ICSI delay&sum signal enhancement system from all available input signals.
Unless otherwise specified, the development experiments were carried out with a BIC penalty
weight 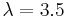 and a SID threshold
and a SID threshold 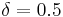 .
.
The performance measure, or speaker diarization error rate (DER), is the fraction of speaker time that is not attributed to the correct speaker, given an optimum speaker mapping between the reference speaker IDs and the hypotheses. In addition, the SAD error only measures speech/non-speech confusions.
| Meeting data | condition | SAD error (%) | DER (%) |
|---|---|---|---|
| conference | MDM | 4.5 | 26.1 |
| conference | SDM | 4.9 | 29.5 |
| lecture | MDM | 2.6 | 25.8 |
| lecture | SDM | 2.9 | 25.6 |
Table 1 summarizes speaker diarization performances in the NIST RT-07S evaluation. The diarization system provides similar diarization results on the beamformed MDM signals for both the RT-07S conference and lecture evaluation data (i.e. a DER of 26.1% for the conference dataset and 25.8% for the lecture dataset). The DER rate increases to 29.5% on the conference SDM data, while for the lecture SDM data, the error rate remains very closely to the one obtained on the beamformed MDM condition.
References
C. Barras, X. Zhu, S. Meignier, and J-L. Gauvain. Multistage Speaker Diarization of Broadcast News. IEEE Transactions on Audio, Speech and Language Processing, 14(5):1505-1512, 2006.
Xuan Zhu, C. Barras, L. Lamel, and J-L. Gauvain. Multi-Stage Speaker Diarization for Conference and Lecture Meetings. In S. Renals, S. Bengio, and J. Fiscus, editors, to appear Lecture Notes in Computer Science, Bethesda, MD, May 2007. Springer Verlag.